
Python爬虫 第2页
-

Python爬虫入门之Urllib库的高级用法
urllib和urllib2库是学习Python爬虫最基本的库,利用这个库我们可以得到网页的内容,并对内容用正则表达式提取分析,得到我们想要的结果。 1.设置Headers有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们...
 kavin
2018.05.12
2495浏览
0
kavin
2018.05.12
2495浏览
0
-

Python爬虫入门之Urllib库的基本使用
urllib和urllib2库是学习Python爬虫最基本的库,利用这个库我们可以得到网页的内容,并对内容用正则表达式提取分析,得到我们想要的结果。1.分分钟扒一个网页下来怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来...
kavin
2018.05.12
2537浏览
0
-

常见Python 爬虫的工具列表枚举
这个列表包含与网页抓取和数据处理的Python库1. 网络通用urllib -网络库(stdlib)。requests -网络库。grab – 网络库(基于pycurl)。pycurl – 网络库(绑定libcurl)。urllib3 – Python HTTP库,安全连接池、支持文件post、可用...
kavin
2018.05.04
2765浏览
0
最新文章
-
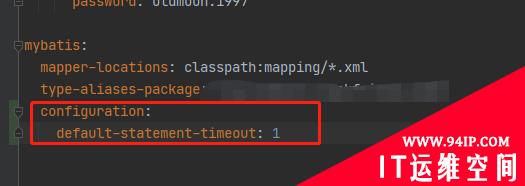
解读springboot配置mybatis的sql执行超时时间(mysql)
2023-02-27 -
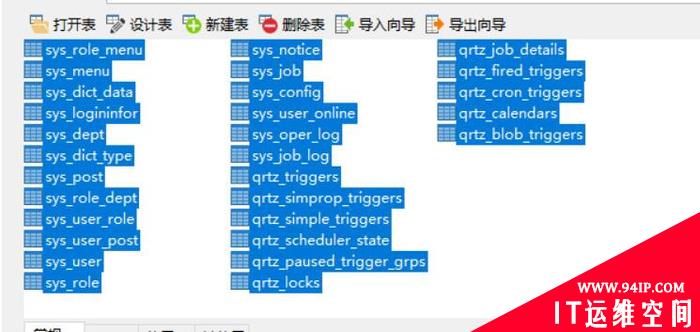
mysql数据库如何转移到oracle
2023-02-27 -

MySQL如何查看正在运行的SQL详解
2023-02-27 -
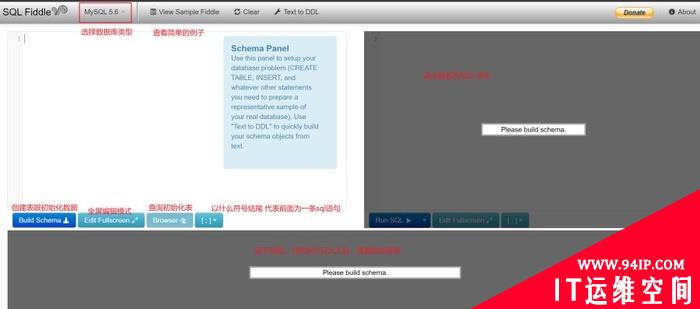
支持在线写SQL的Oracle学习免费网站推荐!(个人常使用)
2023-02-27 -

sql server 与 mysql 中常用的SQL语句区别讲解
2023-02-27 -

浅析Mysql和Oracle分页的区别
2023-02-27 -
mysql数据库操作_高手进阶常用的sql命令语句大全 原创
2023-02-27 -
MySQL动态SQL拼接实例详解
2023-02-27 -
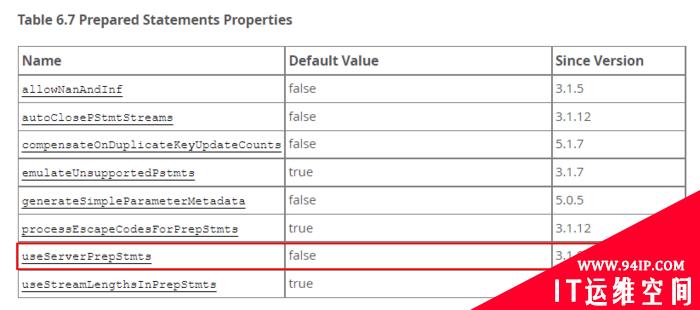
MySQL与JDBC之间的SQL预编译技术讲解
2023-02-27 -
解决MySql版本问题sql_mode=only_full_group_by
2023-02-27