
Python爬虫
-

Python爬虫实战(5):模拟登录淘宝并获取所有订单
本篇内容1. python模拟登录淘宝网页2. 获取登录用户的所有订单详情3. 学会应对出现验证码的情况4. 体会一下复杂的模拟登录机制探索部分成果1. 淘宝的密码用了AES加密算法,最终将密码转化为256位,在POST时,传输的是256位长度的密码。2. 淘宝在登录时必须要输入验证码,在经过几次尝...
 kavin
2018.05.15
2421浏览
0
kavin
2018.05.15
2421浏览
0
-

Python爬虫实战(4):抓取淘宝MM照片
本篇目标1.抓取淘宝MM的姓名,头像,年龄2.抓取每一个MM的资料简介以及写真图片3.把每一个MM的写真图片按照文件夹保存到本地4.熟悉文件保存的过程1.URL的格式在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,...
kavin
2018.05.15
2735浏览
0
-

Python爬虫实战(3):计算大学本学期绩点
本篇目标1.模拟登录学生成绩管理系统2.抓取本学期成绩界面3.计算打印本学期成绩1.URL的获取先贴一个URL,让大家知道学校学生信息系统的网站构架,主页是 http://jwxt.sdu.edu.cn:7890/zhxt_bks/zhxt_bks.html,用了frame,一个多么古老的而又任性的...
kavin
2018.05.15
2802浏览
0
-

Python爬虫实战(2):百度贴吧帖子
上章节我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子。与上一篇不同的是,这次我们需要用到文件的相关操作。本篇目标1.对百度贴吧的任意帖子进行抓取2.指定是否只抓取楼主发帖内容3.将抓取到的内容分析并保存到文件1.URL格式的确定首先,我们先观察一下百度贴吧的任意一个帖子。比...
kavin
2018.05.15
2475浏览
0
-

Python爬虫入门之Beautiful Soup的用法
正则匹配稍有差池,那可能程序就处在永久的循环之中,如果对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Beautiful Soup,有了它我们可以很方便地提取出HTML或XML标签中的内容,实在是方便。1. Beautiful Soup的简介简单来说,Beautiful Soup...
kavin
2018.05.12
2501浏览
0
最新文章
-
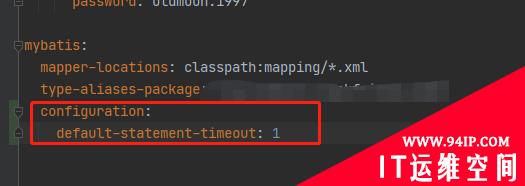
解读springboot配置mybatis的sql执行超时时间(mysql)
2023-02-27 -
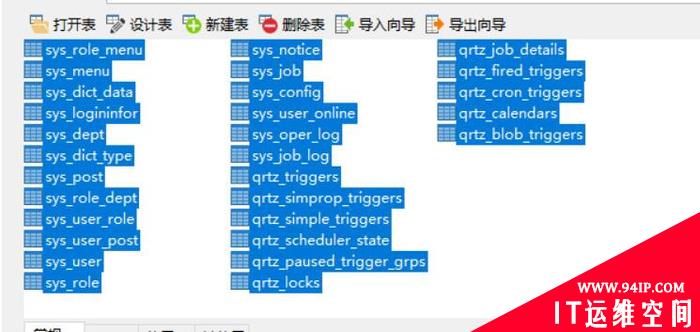
mysql数据库如何转移到oracle
2023-02-27 -
MySQL如何查看正在运行的SQL详解
2023-02-27 -
支持在线写SQL的Oracle学习免费网站推荐!(个人常使用)
2023-02-27 -

sql server 与 mysql 中常用的SQL语句区别讲解
2023-02-27 -

浅析Mysql和Oracle分页的区别
2023-02-27 -

mysql数据库操作_高手进阶常用的sql命令语句大全 原创
2023-02-27 -

MySQL动态SQL拼接实例详解
2023-02-27 -
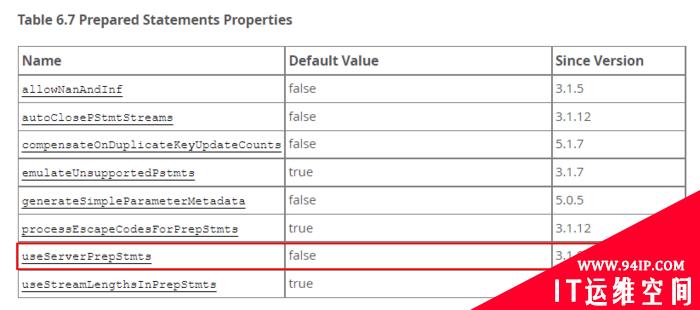
MySQL与JDBC之间的SQL预编译技术讲解
2023-02-27 -
解决MySql版本问题sql_mode=only_full_group_by
2023-02-27