

监控SQL
1.监控事例的等待:
select event,sum(decode(wait_time,0,0,1)) prev, sum(decode(wait_time,0,1,0)) curr,count(*)
from v$session_wait
group by event order by 4;
2.回滚段的争用情况:
select name,waits,gets,waits/gets ratio from v$rollstat a,v$rollname b where a.usn=b.usn;
3.监控表空间的I/O 比例:
select df.tablespace_name name,df.file_name “file”,f.phyrds pyr,f.phyblkrd pbr,f.phywrts pyw,
f.phyblkwrt pbw
from v$filestat f,dba_data_files df
where f.file#=df.file_id
4.监空文件系统的I/O 比例:
select substr(a.file#,1,2) “#”,substr(a.name,1,30) “name”,a.status,a.bytes,
b.phyrds,b.phywrts
from v$datafile a,v$filestat b
where a.file#=b.file#
5.在某个用户下找所有的索引:
select user_indexes.table_name, user_indexes.index_name,uniqueness, column_name
from user_ind_columns, user_indexes
where user_ind_columns.index_name = user_indexes.index_name
and user_ind_columns.table_name = user_indexes.table_name
order by user_indexes.table_type, user_indexes.table_name,
user_indexes.index_name, column_position;
6.进程监控:
select distinct p.spid unix_process,
s.terminal,
to_char(s.logon_time,’YYYY/MON/DD HH24:MI’) Logon_Time,
s.username
from v$process p, v$session s
where p.addr=s.paddr order by 2
7. 监控 SGA 中字典缓冲区的命中率
select parameter, gets,Getmisses , getmisses/(gets+getmisses)*100 “miss ratio”,
(1-(sum(getmisses)/ (sum(gets)+sum(getmisses))))*100 “Hit ratio”
from v$rowcache
where gets+getmisses <>0
group by parameter, gets, getmisses;
8. 监控 SGA ***享缓存区的命中率,应该小于1%
select sum(pins) “Total Pins”, sum(reloads) “Total Reloads”,
sum(reloads)/sum(pins) *100 libcache
from v$librarycache;
select sum(pinhits-reloads)/sum(pins) “hit radio”,sum(reloads)/sum(pins) “reload percent”
from v$librarycache;
9. 显示所有数据库对象的类别和大小
select count(name) num_instances ,type ,sum(source_size) source_size ,
sum(parsed_size) parsed_size ,sum(code_size) code_size ,sum(error_size) error_size,
sum(source_size) +sum(parsed_size) +sum(code_size) +sum(error_size) size_required
from dba_object_size
group by type order by 2;
10. 监控 SGA 中重做日志缓存区的命中率,应该小于1%
SELECT name, gets, misses, immediate_gets, immediate_misses,
Decode(gets,0,0,misses/gets*100) ratio1,
Decode(immediate_gets+immediate_misses,0,0,
immediate_misses/(immediate_gets+immediate_misses)*100) ratio2
FROM v$latch WHERE name IN (‘redo allocation’, ‘redo copy’);
11. 监控内存和硬盘的排序比率,最好使它小于 .10,增加 sort_area_size
SELECT name, value FROM v$sysstat WHERE name IN (‘sorts (memory)’, ‘sorts (disk)’);
12. 监控当前数据库谁在运行什么SQL语句
SELECT osuser, username, sql_text from v$session a, v$sqltext b
where a.sql_address =b.address order by address, piece;
13. 监控字典缓冲区
SELECT (SUM(PINS – RELOADS)) / SUM(PINS) “LIB CACHE” FROM V$LIBRARYCACHE;
SELECT (SUM(GETS – GETMISSES – USAGE – FIXED)) / SUM(GETS) “ROW CACHE” FROM V$ROWCACHE;
SELECT SUM(PINS) “EXECUTIONS”, SUM(RELOADS) “CACHE MISSES WHILE EXECUTING” FROM V$LIBRARYCACHE;
后者除以前者,此比率小于1%,接近0%为好。
SELECT SUM(GETS) “DICTIONARY GETS”,SUM(GETMISSES) “DICTIONARY CACHE GET MISSES”
FROM V$ROWCACHE
14. 找ORACLE 字符集
select * from sys.props$ where name=’NLS_CHARACTERSET’;
15. 监控 MTS
select busy/(busy+idle) “shared servers busy” from v$dispatcher;
此值大于0.5 时,参数需加大
select sum(wait)/sum(totalq) “dispatcher waits” from v$queue where type=’dispatcher’;
select count(*) from v$dispatcher;
select servers_highwater from v$mts;
servers_highwater 接近mts_max_servers 时,参数需加大
16. 碎片程度
select tablespace_name,count(tablespace_name) from dba_free_space group by tablespace_name
having count(tablespace_name)>10;
alter tablespace name coalesce;
alter table name deallocate unused;
create or replace view ts_blocks_v as
select tablespace_name,block_id,bytes,blocks,’free space’ segment_name from dba_free_space
union all
select tablespace_name,block_id,bytes,blocks,segment_name from dba_extents;
select * from ts_blocks_v;
select tablespace_name,sum(bytes),max(bytes),count(block_id) from dba_free_space
group by tablespace_name;
查看碎片程度高的表
SELECT segment_name table_name , COUNT(*) extents
FROM dba_segments WHERE owner NOT IN (‘SYS’, ‘SYSTEM’) GROUP BY segment_name
HAVING COUNT(*) = (SELECT MAX( COUNT(*) ) FROM dba_segments GROUP BY segment_name);
17. 表、索引的存储情况检查
select segment_name,sum(bytes),count(*) ext_quan from dba_extents where
tablespace_name=’&tablespace_name’ and segment_type=’TABLE’ group by
tablespace_name,segment_name;
select segment_name,count(*) from dba_extents where segment_type=’INDEX’ and owner=’&owner’
group by segment_name;
18、找使用CPU 多的用户session
12 是cpu used by this session
select a.sid,spid,status,substr(a.program,1,40) prog,a.terminal,osuser,value/60/100 value
from v$session a,v$process b,v$sesstat c
where c.statistic#=12 and c.sid=a.sid and a.paddr=b.addr order by value desc;
20.监控log_buffer 的使用情况:(值最好小于1%,否则增加log_buffer 的大小)
select rbar.name,rbar.value,re.name,re.value,(rbar.value*100)/re.value||’%’ “radio”
from v$sysstat rbar,v$sysstat re
where rbar.name=’redo buffer allocation retries’
and re.name=’redo entries’;
19、查看运行过的SQL 语句:
SELECT SQL_TEXT
FROM V$SQL
常用用户SQL
表:
select * from cat;
select * from tab;
select table_name from user_tables;
视图:
select text from user_views where view_name=upper(‘&view_name’);
索引:
select index_name,table_owner,table_name,tablespace_name,status from user_indexes order by
table_name;
触发器:
select trigger_name,trigger_type,table_owner,table_name,status from user_triggers;
快照:
select owner,name,master,table_name,last_refresh,next from user_snapshots order by
owner,next;
同义词:
select * from syn;
序列:
select * from seq;
数据库链路:
select * from user_db_links;
约束限制:
select TABLE_NAME,CONSTRAINT_NAME,SEARCH_CONDITION,STATUS
from user_constraints WHERE TABLE_name=upper(‘&TABLE_Name’);
本用户读取其他用户对象的权限:
select * from user_tab_privs;
本用户所拥有的系统权限:
select * from user_sys_privs;
用户:
select * from all_users order by user_id;
表空间剩余***空间情况:
select tablespace_name,sum(bytes) 总字节数,max(bytes),count(*) from dba_free_space group
by tablespace_name;
数据字典:
select table_name from dict order by table_name;
锁及资源信息:
select * from v$lock;不包括DDL 锁
数据库字符集:
select name,value$ from props$ where name=’NLS_CHARACTERSET’;
inin.ora 参数:
select name,value from v$parameter order by name;
SQL 共享池:
select sql_text from v$sqlarea;
数据库:
select * from v$database
控制文件:
select * from V$controlfile;
重做日志文件信息:
select * from V$logfile;
来自控制文件中的日志文件信息:
select * from V$log;
来自控制文件中的数据文件信息:
select * from V$datafile;
NLS 参数当前值:
select * from V$nls_parameters;
ORACLE 版本信息:
select * from v$version;
描述后台进程:
select * from v$bgprocess;
查看版本信息:
select * from product_component_version;
查询表结构
select substr(table_name,1,20) tabname,
substr(column_name,1,20)column_name,
rtrim(data_type)||'(‘||data_length||’)’ from system.dba_tab_columns
where owner=’username’
表空间使用状态
select a.file_id “FileNo”,a.tablespace_name “Tablespace_name”,
round(a.bytes/1024/1024,4) “Total MB”,
round((a.bytes-sum(nvl(b.bytes,0)))/1024/1024,4) “Used MB”,
round(sum(nvl(b.bytes,0))/1024/1024,4) “Free MB”,
round(sum(nvl(b.bytes,0))/a.bytes*100,4) “%Free”
from dba_data_files a, dba_free_space b
where a.file_id=b.file_id(+)
group by a.tablespace_name,
a.file_id,a.bytes order by a.tablespace_name
查询某个模式下面数据不为空的表
declare
Cursor c is select TNAME from tab;
vCount Number;
table_nm Varchar2(100);
sq varchar2(300);
begin
for r in c loop
table_nm:=r.TNAME;
sq:=’select count(*) from ‘|| table_nm;
execute immediate sq into vCount;
if vCount>0 then
dbms_output.put_line(r.tname);
end if;
end loop;
end;
客户端主机信息
SELECT
SYS_CONTEXT(‘USERENV’,’TERMINAL’) TERMINAL,
SYS_CONTEXT(‘USERENV’,’HOST’) HOST,
SYS_CONTEXT(‘USERENV’,’OS_USER’) OS_USER,
SYS_CONTEXT(‘USERENV’,’IP_ADDRESS’) IP_ADDRESS
FROM DUAL
安装Oracle 后,经常使用的修改表空间的SQL 代码
配置:
Windows NT 4.0 中文版
5 块10.2GB SCSI 硬盘
分:C:盘、D:盘、E:盘、F:盘、G:盘
Oracle 8.0.4 for Windows NT
NT 安装在C:\WINNT,Oracle 安装在C:\ORANT
目标:
因系统的回滚段太小,现打算生成新的回滚段,
建立大的、新的表空间(数据表空间、索引表空间、回滚表空间、临时表空间、)
建两个数据表空间、两个索引表空间,这样建的目的是根据实际应用,
如:现有10 个应用用户,每个用户是一个独立子系统(如:商业进销存MIS系统中的财务、收款、库存、
人事、总经理等)
尤其大型商场中收款机众多,同时访问进程很多,经常达到50-100 个进程同时访问,
这样,通过建立多个用户表空间、索引表空间,把各个用户分别建在不同的表空间里(多个用户表空间放
在不同的物理磁盘上),
减少了用户之间的I/O 竞争、读写数据与写读索引的竞争(用户表空间、索引表空间也分别放在不同的物
理磁盘上)
规划:
C:盘、NT 系统,Oracle 系统
D:盘、数据表空间1(3GB、自动扩展)、回滚表空间1(1GB、自动扩展)
E:盘、数据表空间2(3GB、自动扩展)、回滚表空间2(1GB、自动扩展)
F:盘、索引表空间1(2GB、自动扩展)、临时表空间1(0.5GB、不自动扩展)
G:盘、索引表空间2(2GB、自动扩展)、临时表空间2(0.5GB、不自动扩展)
注:这只是一个简单的规划,实际规划要依系统需求来定,尽量减少I/O 竞争
实现:
1、首先查看系统有哪些回滚段及其状态。
SQL> col owner format a20
SQL> col status format a10
SQL> col segment_name format a20
SQL> col tablespace_name format a20
SQL> SELECT OWNER,SEGMENT_NAME,TABLESPACE_NAME,SUM(BYTES)/1024/1024 M
2 FROM DBA_SEGMENTS
3 WHERE SEGMENT_TYPE=’ROLLBACK’
4 GROUP BY OWNER,SEGMENT_NAME,TABLESPACE_NAME
5 /
OWNER SEGMENT_NAME TABLESPACE_NAME M
——————– ——————– ——————– ———
SYS RB1 ROLLBACK_DATA .09765625
SYS RB10 ROLLBACK_DATA .09765625
SYS RB11 ROLLBACK_DATA .09765625
SYS RB12 ROLLBACK_DATA .09765625
SYS RB13 ROLLBACK_DATA .09765625
SYS RB14 ROLLBACK_DATA .09765625
SYS RB15 ROLLBACK_DATA .09765625
SYS RB16 ROLLBACK_DATA .09765625
SYS RB2 ROLLBACK_DATA .09765625
SYS RB3 ROLLBACK_DATA .09765625
SYS RB4 ROLLBACK_DATA .09765625
SYS RB5 ROLLBACK_DATA .09765625
SYS RB6 ROLLBACK_DATA .09765625
SYS RB7 ROLLBACK_DATA .09765625
SYS RB8 ROLLBACK_DATA .09765625
SYS RB9 ROLLBACK_DATA .09765625
SYS RB_TEMP SYSTEM .24414063
SYS SYSTEM SYSTEM .1953125
查询到18记录.
SQL> SELECT SEGMENT_NAME,OWNER,
2 TABLESPACE_NAME,SEGMENT_ID,FILE_ID,STATUS
3 FROM DBA_ROLLBACK_SEGS
4 /
SEGMENT_NAME OWNER TABLESPACE_NAME SEGMENT_ID FILE_ID STATUS
——————– ——————– ——————– ———- ——— ———-
SYSTEM SYS SYSTEM 0 1 ONLINE
RB_TEMP SYS SYSTEM 1 1 OFFLINE
RB1 PUBLIC ROLLBACK_DATA 2 3 ONLINE
RB2 PUBLIC ROLLBACK_DATA 3 3 ONLINE
RB3 PUBLIC ROLLBACK_DATA 4 3 ONLINE
RB4 PUBLIC ROLLBACK_DATA 5 3 ONLINE
RB5 PUBLIC ROLLBACK_DATA 6 3 ONLINE
RB6 PUBLIC ROLLBACK_DATA 7 3 OFFLINE
RB7 PUBLIC ROLLBACK_DATA 8 3 OFFLINE
RB8 PUBLIC ROLLBACK_DATA 9 3 OFFLINE
RB9 PUBLIC ROLLBACK_DATA 10 3 OFFLINE
RB10 PUBLIC ROLLBACK_DATA 11 3 OFFLINE
RB11 PUBLIC ROLLBACK_DATA 12 3 OFFLINE
RB12 PUBLIC ROLLBACK_DATA 13 3 OFFLINE
RB13 PUBLIC ROLLBACK_DATA 14 3 OFFLINE
RB14 PUBLIC ROLLBACK_DATA 15 3 OFFLINE
RB15 PUBLIC ROLLBACK_DATA 16 3 OFFLINE
RB16 PUBLIC ROLLBACK_DATA 17 3 OFFLINE
查询到18记录.
2、修改代码如下,可把以下代码存入一.sql 文件,如cg_sys.sql,然后以SQL> @cg_sys.sql调用执行。
—注意:各个硬盘上要事先建好oradata 目录
—修改现有回滚段,使之失效,下线
alter rollback segment rb1 offline;
alter rollback segment rb2 offline;
alter rollback segment rb3 offline;
alter rollback segment rb4 offline;
alter rollback segment rb5 offline;
alter rollback segment rb6 offline;
alter rollback segment rb7 offline;
alter rollback segment rb8 offline;
alter rollback segment rb9 offline;
alter rollback segment rb10 offline;
alter rollback segment rb11 offline;
alter rollback segment rb12 offline;
alter rollback segment rb13 offline;
alter rollback segment rb14 offline;
alter rollback segment rb15 offline;
alter rollback segment rb16 offline;
—删除原有回滚段
drop rollback segment rb1;
drop rollback segment rb2;
drop rollback segment rb3;
drop rollback segment rb4;
drop rollback segment rb5;
drop rollback segment rb6;
drop rollback segment rb7;
drop rollback segment rb8;
drop rollback segment rb9;
drop rollback segment rb10;
drop rollback segment rb11;
drop rollback segment rb12;
drop rollback segment rb13;
drop rollback segment rb14;
drop rollback segment rb15;
drop rollback segment rb16;
—建数据表空间1
—收款、库存、订货、远程通信
create tablespace USER_DATA1 datafile
‘d:\oradata\user1_1.ora’ size 512M,
‘d:\oradata\user1_2.ora’ size 512M,
‘d:\oradata\user1_3.ora’ size 512M,
‘d:\oradata\user1_4.ora’ size 512M,
‘d:\oradata\user1_5.ora’ size 512M,
‘d:\oradata\user1_6.ora’ size 512M
AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED
default storage (initial 128K next 2M pctincrease 0);
–initial 128K,因为,用户建在表空间上,而表建在用户里,为用户所拥有,
—用户继承数据表空间的存储参数,表继承用户的存储参数
—如果initial 设的过大,如:5M,则每建一个空表就要占用5M 的空间,即使一条记录也没有
–AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED,设置数据文件自动扩展,每一次扩展增加5M,最大空间
不受限
—建数据表空间2
—物价、人事、结算、财务、总经理、合同、统计
create tablespace USER_DATA2 datafile
‘e:\oradata\user2_1.ora’ size 512M,
‘e:\oradata\user2_2.ora’ size 512M,
‘e:\oradata\user2_3.ora’ size 512M,
‘e:\oradata\user2_4.ora’ size 512M,
‘e:\oradata\user2_5.ora’ size 512M,
‘e:\oradata\user2_6.ora’ size 512M
AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED
default storage (initial 128K next 2M pctincrease 0);
—建索引表空间1
create tablespace INDEX_DATA1 datafile
‘f:\oradata\index1_1.ora’ size 512M,
‘f:\oradata\index1_2.ora’ size 512M,
‘f:\oradata\index1_3.ora’ size 512M,
‘f:\oradata\index1_4.ora’ size 512M
AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED
default storage (initial 128K next 2M pctincrease 0);
—建索引表空间2
create tablespace INDEX_DATA2 datafile
‘g:\oradata\index2_1.ora’ size 512M,
‘g:\oradata\index2_2.ora’ size 512M,
‘g:\oradata\index2_3.ora’ size 512M,
‘g:\oradata\index2_4.ora’ size 512M
AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED
default storage (initial 128K next 2M pctincrease 0);
—建回滚表空间1
—设置初始值40M(initial 40M),则每在这个表空间中建一个回滚段,
—此回滚段自动继承此回滚表空间的存储参数,也即默认文件为40M
create tablespace ROLLBACK_DATA1 datafile
‘d:\oradata\roll1_1.ora’ size 512M,
‘d:\oradata\roll1_2.ora’ size 512M
AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED
default storage (initial 40M next 5M pctincrease 0);
—建回滚表空间2
create tablespace ROLLBACK_DATA2 datafile
‘e:\oradata\roll2_1.ora’ size 512M,
‘e:\oradata\roll2_2.ora’ size 512M
AUTOEXTEND ON NEXT 5M MAXSIZE UNLIMITED
default storage (initial 40M next 5M pctincrease 0);
—建临时表空间1
create tablespace TEMPORARY_DATA1 datafile
‘f:\oradata\temp1_1.ora’ size 512M
default storage (initial 10M next 3M pctincrease 0);
—建临时表空间2
create tablespace TEMPORARY_DATA2 datafile
‘g:\oradata\temp2_1.ora’ size 512M
default storage (initial 10M next 3M pctincrease 0);
—使其真正成为临时的
alter tablespace TEMPORARY_DATA1 temporary;
alter tablespace TEMPORARY_DATA2 temporary;
—建立新的回滚段,每个都一样大,不同大小的回滚段没有什么意义,系统是随机选择的。
—建多少个,根据并发访问用户的多少,
—如果你们公司每天有50-100 个人员使用Oracle系统开发的管理软件,应该20 个以上
create public rollback segment rb01 tablespace rollback_data1;
create public rollback segment rb02 tablespace rollback_data1;
create public rollback segment rb03 tablespace rollback_data1;
create public rollback segment rb04 tablespace rollback_data1;
create public rollback segment rb05 tablespace rollback_data1;
create public rollback segment rb06 tablespace rollback_data1;
create public rollback segment rb07 tablespace rollback_data1;
create public rollback segment rb08 tablespace rollback_data1;
create public rollback segment rb09 tablespace rollback_data2;
create public rollback segment rb10 tablespace rollback_data2;
—前8 个建在回滚表空间1 中,后8 个在回滚表空间2
create public rollback segment rb11 tablespace rollback_data2;
create public rollback segment rb12 tablespace rollback_data2;
create public rollback segment rb13 tablespace rollback_data2;
create public rollback segment rb14 tablespace rollback_data2;
create public rollback segment rb15 tablespace rollback_data2;
create public rollback segment rb16 tablespace rollback_data2;
create public rollback segment rb17 tablespace rollback_data2;
create public rollback segment rb18 tablespace rollback_data2;
create public rollback segment rb19 tablespace rollback_data2;
create public rollback segment rb20 tablespace rollback_data2;
—使回滚段online,即有效
alter rollback segment rb01 online;
alter rollback segment rb02 online;
alter rollback segment rb03 online;
alter rollback segment rb04 online;
alter rollback segment rb05 online;
alter rollback segment rb06 online;
alter rollback segment rb07 online;
alter rollback segment rb08 online;
alter rollback segment rb09 online;
alter rollback segment rb10 online;
alter rollback segment rb11 online;
alter rollback segment rb12 online;
alter rollback segment rb13 online;
alter rollback segment rb14 online;
alter rollback segment rb15 online;
alter rollback segment rb16 online;
alter rollback segment rb17 online;
alter rollback segment rb18 online;
alter rollback segment rb19 online;
alter rollback segment rb20 online;
—查看现有回滚段及其状态
col segment format a30
SELECT SEGMENT_NAME,OWNER,TABLESPACE_NAME,SEGMENT_ID,FILE_ID,STATUS FROM DBA_ROLLBACK_SEGS;
—查看数据文件及其所在表空间、大小、状态
col file_name format a40
col tablespace_name format a20
select file_name,file_id,tablespace_name,bytes,status from dba_data_files;
至此,表空间重新规划完毕,这里讲的比较通俗,还有好多参数值得设置,能够把Oracle 设置到最优的
境界,
表空间设置完了,下面,就该好好的整理一下Oracle 的内存区了,
Oracle 很有意思,内存越大,效果越明显,所以有必要好好调整一下SGA 区,也就是主要配置ininorcl.ora
参数文件。
查看回滚段名称及大小
COLUMN roll_name FORMAT a13 HEADING ‘Rollback Name’
COLUMN tablespace FORMAT a11 HEADING ‘Tablspace’
COLUMN in_extents FORMAT a20 HEADING ‘Init/Next Extents’
COLUMN m_extents FORMAT a10 HEADING ‘Min/Max Extents’
COLUMN status FORMAT a8 HEADING ‘Status’
COLUMN wraps FORMAT 999 HEADING ‘Wraps’
COLUMN shrinks FORMAT 999 HEADING ‘Shrinks’
COLUMN opt FORMAT 999,999,999 HEADING ‘Opt. Size’
COLUMN bytes FORMAT 999,999,999 HEADING ‘Bytes’
COLUMN extents FORMAT 999 HEADING ‘Extents’
SELECT
a.owner || ‘.’ || a.segment_name roll_name
, a.tablespace_name tablespace
, TO_CHAR(a.initial_extent) || ‘ / ‘ ||
TO_CHAR(a.next_extent) in_extents
, TO_CHAR(a.min_extents) || ‘ / ‘ ||
TO_CHAR(a.max_extents) m_extents
, a.status status
, b.bytes bytes
, b.extents extents
, d.shrinks shrinks
, d.wraps wraps
, d.optsize opt
FROM
dba_rollback_segs a
, dba_segments b
, v$rollname c
, v$rollstat d
WHERE
a.segment_name = b.segment_name
AND a.segment_name = c.name (+)
AND c.usn = d.usn (+)
ORDER BY a.segment_name;
PL/SQL 入门教程
1.1 PL/SQL 简介
PL/SQL是ORACLE的过程化语言,包括一整套的数据类型、条件结构、循环结构和异常处理结构,PL/SQL
可以执行SQL 语句,SQL 语句中也可以使用PL/SQL 函数。
1.2 创建PL/SQL 程序块
DECLARE
…
BEGIN
…
EXCEPTION
END;
1.3 PL/SQL 数据类型
名称
类型
说明
NUMBER
数字型
能存放整数值和实数值,并且可以定义精度和取值范围
BINARY_INTEGER
数字型
可存储带符号整数,为整数计算优化性能
DEC
数字型
NUMBER 的子类型,小数
DOUBLE PRECISION
数字型
NUMBER 的子类型,高精度实数
INTEGER
数字型
NUMBER 的子类型,整数
INT
数字型
NUMBER 的子类型,整数
NUMERIC
数字型
NUMBER 的子类型,与NUMBER 等价
REAL
数字型
NUMBER 的子类型,与NUMBER 等价
SMALLINT
数字型
NUMBER 的子类型,取值范围比INTEGER 小
VARCHAR2
字符型
存放可变长字符串,有最大长度
CHAR
字符型
定长字符串
LONG
字符型
变长字符串,最大长度可达32,767
DATE
日期型
以数据库相同的格式存放日期值
BOOLEAN
布尔型
TRUE OR FALSE
ROWID
ROWID
存放数据库的行号
例_____子:
DECLARE
ORDER_NO NUMBER(3);
CUST_NAME VARCHAR2(20);
ORDER_DATE DATE;
EMP_NO INTEGER:=25;
PI CONSTANT NUMBER:=3.1416;
BEGIN
NULL;
END;
1.4 处理PL/SQL 的异常
1.4.1 PL/SQL 的异常
例如:
DECLARE
X NUMBER;
BEGIN
X:= ‘yyyy’;–Error Here
EXCEPTION WHEN VALUE_ERROR THEN
DBMS_OUTPUT.PUT_LINE(‘EXCEPTION HANDED’);
END;
实现技术:
EXCEPTION WHEN first_exception THEN
…
WHEN second_exception THEN
…
WHEN OTHERS THEN
/*THERS 异常处理器必须排在最后,它处理所有没有明确列出的异常。*/
…
END;
1.4.2 预定义异常
异常名称
ORACLE 错误
说明
CURSOR_ALREADY_OPEN
ORA-6511
试图打开一个已打开的光标
DUP_VAL_ON_INDEX
ORA-0001
试图破坏一个唯一性限制
INVALID_CURSOR
ORA-1001
试图使用一个无效的光标
INVALID_NUMBER
ORA-1722
试图对非数字值进行数字操作
LOGIN_DENIED
ORA-1017
无效的用户名或者口令
NO_DATA_FOUND
ORA-1403
查询未找到数据
NOT_LOGGED_ON
ORA-1012
还未连接就试图数据库操作
PROGRAM_ERROR
ORA-6501
内部错误
ROWTYPE_MISMATCH
ORA-6504
主变量和光标的类型不兼容
STORAGE_ERROR
ORA-6500
内部错误
TIMEOUT_ON_RESOURCE
ORA-0051
发生超时
TOO_MANY_ROWS
ORA-1422
SELECT INTD 命令返回的多行
TRANSACTION_BACKED_OUT
ORA-006
由于死锁提交被退回
VALUE_ERROR
ORA-6502
转换或者裁剪错误
ZERO_DIVIDE
ORA-1476
试图被零除
1.4.3 自定义异常处理
DECLARE
BAD_ROWID EXCEPTION;
X ROWID;
PRAGMA EXCEPTION_INIT(BAD_ROWID,-01445);
BEGIN
SELECT ROWID INTO X FROM TAB
WHERE ROWNUM=1;
EXCEPTION WHEN BAD_ROWID THEN
DBMS_OUTPUT.PUT_LINE(‘CANNOT QUERY ROWID FROM THIS VIEW’);
END;
注意:-01445 因为PRAGMA EXCEPTION_INIT 命令把这个变量(-01455)连接到
这个ORACLE 错误,该语句的语法如下:
PRAGMA EXCEPTION_INIT(exception_name, error_number);
其中error_number 是负数,因为错误号被认为负数,当定义错误时记住使用负号
1.4.4 自定义异常
异常不一定必须是oracle 返回的系统错误,用户可以在自己的应用程序中创
建可触发及可处理的自定义异常
DECLARE
SALARY_CODE VARCHAR2(1);
INVALID_SALARY_CODE EXCEPTION;
BEGIN
SALARY_CODE:=’X’;
IF SALARY_CODE NOT IN(‘A’, ‘B’, ‘C’) THEN
RAISE INVALID_SALARY_CODE;
END IF;
EXCEPTION WHEN INVALID_SALARY_CODE THEN
DBMS_OUTPUT.PUT_LINE(‘INVALID SALARY CODE’);
END;
1.5 在PL/SQL 中单条记录的查询
在PL/SQL内,有时在没有定义显式光标的情况下需要查询单条记录,并把记录的数据赋给变量。
DECLARE
ln_dno NUMBER;
lvs_dname VARCHAR2(40);
BEGIN
SELECT DEPT_NO,DEPT_NAME
INTO ln_dno,lvs_dname
FROM dept
WHERE DEPT_NO=1;
DBMS_OUTPUT.PUT_LINE(TO_CHAR(ln_dno)||’.’||lvs_dname);
EXCEPTION WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE(‘NO DATA_FOUND’);
WHEN TOO_MANY_ROWS THEN
DBMS_OUTPUT.PUT_LINE(‘TOO_MANY_ROWS’);
END;
1.6 用光标查询多条记录
光标(CURSOR)是指向一个称为上下文相关区的区域的指针,这个区域在服务器的处理过程全局区
(PGA)内,当服务器上执行了一个查询后,查询返回的记录集存放在上下文相关区,通过光标上的操作
可以把这些记录检索到客户端的应用程序。
1.6.1 使用光标的基本方法
DECLARE
CURSOR C1 IS SELECT VIEW_NAME FROM ALL_VIEWS
WHERE ROWNUM<=10
ORDER BY VIEW_NAME;
VNAME VARCHAR2(40);
BEGIN
OPEN C1;
FETCH C1 INTO VNAME;
WHILE C1%FOUND LOOP
DBMS_OUTPUT.PUT_LINE(TO_CHAR(C1%ROWCOUNT)||’ ‘||VNAME);
FETCH C1 INTO VNAME;
END LOOP;
END;
属性
含量
%FOUND
布尔型属性,当最近一次该记录时成功返回,则值为TRUE
%NOTFOUND
布尔型属性,它的值总与%FOUND 属性的值相反
%ISOPEN
布尔型属_____性,当光标是打开时返回TRUE
%ROWCOUNT
数字型属性,返回已从光标中读取的记录数
1.6.2 使用光标FOR 循环
DECLARE
CURSOR C1 IS
SELECT VIEW_NAME
FROM ALL_VIEWS
WHERE ROWNUM<=10
ORDER BY VIEW_NAME;
BEGIN
FOR I IN C1 LOOP
DBMS_OUTPUT.PUT_LINE(I.VIEW_NAME);
END LOOP;
END LOOP;
EXCEPTION WHEN OTHERS THEN
NULL;
END;
1.6.3 带参数的光标
DECLARE
CURSOR C1(VIEW_PATTERN VARCHAR2) IS
SELECT VIEW_NAME
FROM ALL_VIEWS
WHERE VIEW_NAME LIKE VIEW_PATTERN||’%’ AND
ROWNUM<=10
ORDER BY VIEW_NAME;
VNAME VARCHAR2(40);
BEGIN
FOR I IN C1(‘USER_AR’) LOOP
DBMS_OUTPUT.PUT_LINE(I.VIEW_NAME);
END LOOP;
DBMS_OUTPUT.PUT_LINE( );
FOR I IN C1(‘USER’) LOOP
DBMS_OUTPUT.PUT_LINE(I.VIEW_NAME);
END LOOP;
EXCEPTION WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(‘AAA’);
END;
1.7 创建代表数据库记录和列的变量
变量名基表名.列名%TYPE
DECLARE
D_NO DEPT.DEPT_NO%TYPE;
D_NAME DEPT.DEPT_NAME%TYPE;
BEGIN
SELECT DEPT_NO,DEPT_NAME INTO D_NO,D_NAME
FROM DEPT;
DBMS_OUTPUT.PUT_LINE(TO_CHAR(D_NO));
EXCEPTION WHEN NO_DATA_FOUND THEN
NULL;
END;
变量名基表名%ROWTYPE
DECLARE
D VEQU12%ROWTYPE;
BEGIN
SELECT ASSET12ID,ASSET12NAME
INTO D.ASSET12ID, D.ASSET12NAME
FROM VEQU12;
DBMS_OUTPUT.PUT_LINE(D.ASSET12ID);
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
WHEN TOO_MANY_ROWS THEN
DBMS_OUTPUT.PUT_LINE(‘TOO_MANY_ROWS’);
END;
说明:
当用户要创建一个变量来表示一个基表列或者要创建多个变量来代表一整条记录时,可以实际使用
%TYPE 属性和%ROWTYPE 属性,使用%TYPE 属性和%ROWTYPE 属性可以保证当基表的结构或者其中某列的数据
类型改变了时,用户的PL/SQL 代码仍可正常工作。
1.9 怎样用PL/SQL 表实现数组功能
PL/SQL 表与其他过程化语言(如C 语言)的一维数组类似。实现PL/SQL 表需要创建一个数据类型并另
外进行变量说明。
Type <类型名> Is
Table Of <数据类型>
Index by Binary_Integer;
以下为一个例子:
Declare
Type Array_type is
Table Of Number
Index by Binary_Integer;
My_Array Array_type;
Begin
For I In 1..10 Loop
My_Array(I) := I*2;
End Loop;
For I In 1..10 Loop
Dbms_Output.Put_line(To_char(My_Array(I)));
End Loop;
End;
在from 后面使用变量
CREATE OR REPLACE FUNCTION GET_TABLE_COUNT(
I_TabNa IN VARCHAR2 ,
I_Owner IN VARCHAR2 DEFAULT NULL
)
RETURN NUMBER
IS
V_RtnVal NUMBER ;
V_CursorId INTEGER ;
V_SqlStr VARCHAR2(300) ;
BEGIN
V_CursorId := DBMS_SQL.OPEN_CURSOR ;
IF LENGTHB( RTRIM( LTRIM( NVL( I_Owner , ” ) ) ) ) = 0 THEN
V_SqlStr := ‘SELECT COUNT(*) FROM ‘ || I_TabNa ;
ELSE
V_SqlStr := ‘SELECT COUNT(*) FROM ‘ || I_Owner|| ‘.’ || I_TabNa ;
END IF ;
DBMS_SQL.PARSE( V_CursorId , V_SqlStr , DBMS_SQL.V7 ) ;
DBMS_SQL.DEFINE_COLUMN( V_CursorId , 1 , 0 ) ;
IF DBMS_SQL.EXECUTE( V_CursorId ) = 0 THEN
NULL ;
END IF ;
IF DBMS_SQL.FETCH_ROWS( V_CursorId ) = 0 THEN
RETURN 0 ;
END IF ;
DBMS_SQL.COLUMN_VALUE( V_CursorId , 1 , V_RtnVal ) ;
DBMS_SQL.CLOSE_CURSOR( V_CursorId ) ;
RETURN V_RtnVal ;
EXCEPTION
WHEN OTHERS THEN
DBMS_SQL.CLOSE_CURSOR( V_CursorId ) ;
— DBMS_OUTPUT.PUT_LINE( V_SqlStr || SQLERRM ) ;
RETURN 0 ;
END GET_TABLE_COUNT;
试验结果:
SQL> select GET_TABLE_COUNT( ‘tab’ ) from dual ;
GET_TABLE_COUNT(‘TAB’)
———————-
22
SQL> select GET_TABLE_COUNT( ‘spr’ , ‘testman’) from dual ;
GET_TABLE_COUNT(‘SPR’,’TESTMAN
——————————
15
SQL> select GET_TABLE_COUNT( ‘U_Oausr’ , ‘tm’) from dual ;
GET_TABLE_COUNT(‘U_OAUSR’,’TM’
——————————
10
SQL>
说明:
— DBMS_SQL.DEFINE_COLUMN( V_CursorId , 1 , 0 ) ; 里的“0”是什么意思?
DEFINE_COLUMN 是用作定义数据类型的,不同的数据类型有不太的定义方式,这里面的“0”通俗点说就是
“与‘0’一样的数据类型的意思”,比如定义长度为200 的varchar2 型的列的时候,可以简化为这样定
义:DBMS_SQL.DEFINE_COLUMN( V_CursorId , 1 , ‘tmpStr’ , 200 ),更多的数据类型列的定义请查看
oracle 的pl/sql 文档,里面很全。
— 另外,怎么用联编变量?
联编变量是一种非常好的传递参数的方式,而且不容易出错。但是既然称之为“联编变量”那就是它只能
对Oracle 中认为的变量进行联编,而刚才上面的例子中,表面是不能够作为变量的,因此不可以联编,
Oracle 中认为出现在逻辑表达式右边的才是变量,例如可以这样进行_____联编变量:
……
V_SqlStr := ‘SELECT COUNT(*) FROM TAB WHERE TName LIKE :I_Arg0 ‘ ;
DBMS_SQL.PARSE( V_CursorId , V_SqlStr , DBMS_SQL.V7 ) ;
V_TabName := ‘MYTAB’ ;
DBMS_SQL.BIND_VARIABLE( V_CursorId , ‘:I_Arg0’ , V_TabName || ‘%’ ) ;
……
8i 以后的版本这样写也行
CREATE OR REPLACE FUNCTION GET_TABLE_COUNT(
I_TabNa IN VARCHAR2 ,
I_Owner IN VARCHAR2 DEFAULT NULL
)
RETURN NUMBER
IS
V_RtnVal NUMBER ;
V_TabName VARCHAR2(300) ;
BEGIN
IF LENGTHB( RTRIM( LTRIM( NVL( I_Owner , ” ) ) ) ) = 0 THEN
V_TabName := I_TabNa ;
ELSE
V_TabName := I_Owner|| ‘.’ || I_TabNa ;
END IF ;
EXECUTE IMMEDIATE ‘SELECT COUNT(*) FROM ‘ || V_TabName INTO V_RtnVal ;
RETURN V_RtnVal ;
EXCEPTION
WHEN OTHERS THEN
RETURN 0 ;
END GET_TABLE_COUNT ;
Oracle 常用数据字典
视图名描述
ALL_CATALOG All tables, views, synonyms, sequences accessible to the user
ALL_COL_COMMENTS Comments on columns of accessible tables and views
ALL_COL_GRANTS_MADE Grants on columns for which the user is owner or grantor
ALL_COL_GRANTS_RECD Grants on columns for which the user or PUBLIC is the grantee
ALL_COL_PRIVS Grants on columns for which the user is the grantor, grantee, owner, or
an enabled role or PUBLIC is the grantee
ALL_COL_PRIVS_MADE Grants on columns for which the user is owner or grantor
ALL_COL_PRIVS_RECD Grants on columns for which the user, PUBLIC or enabled role is the
grantee
ALL_CONSTRAINTS Constraint definitions on accessible tables
ALL_CONS_COLUMNS Information about accessible columns in constraint definitions
ALL_DB_LINKS Database links accessible to the user
ALL_DEF_AUDIT_OPTS Auditing options for newly created objects
ALL_DEPENDENCIES Dependencies to and from objects accessible to the user
ALL_ERRORS Current errors on stored objects that user is allowed to create
ALL_INDEXES Descriptions of indexes on tables accessible to the user
ALL_IND_COLUMNS COLUMNs comprising INDEXes on accessible TABLES
ALL_OBJECTS Objects accessible to the user
ALL_REFRESH All the refresh groups that the user can touch
ALL_REFRESH_CHILDREN All the objects in refresh groups, where the user can touch the group
ALL_SEQUENCES Description of SEQUENCEs accessible to the user
ALL_SNAPSHOTS Snapshots the user can look at
ALL_SOURCE Current source on stored objects that user is allowed to create
ALL_SYNONYMS All synonyms accessible to the user
ALL_TABLES Description of tables accessible to the user
ALL_TAB_COLUMNS Columns of all tables, views and clusters
ALL_TAB_COMMENTS Comments on tables and views accessible to the user
ALL_TAB_GRANTS_MADE User’s grants and grants on user’s objects
ALL_TAB_GRANTS_RECD Grants on objects for which the user or PUBLIC is the grantee
ALL_TAB_PRIVS Grants on objects for which the user is the grantor, grantee, owner, or
an enabled role or PUBLIC is the grantee
ALL_TAB_PRIVS_MADE User’s grants and grants on user’s objects
ALL_TAB_PRIVS_RECD Grants on objects for which the user, PUBLIC or enabled role is the grantee
ALL_TRIGGERS Triggers accessible to the current user
ALL_TRIGGER_COLS Column usage in user’s triggers or in triggers on user’s tables
ALL_USERS Information about all users of the database
ALL_VIEWS Text of views accessible to the user
USER_AUDIT_CONNECT Audit trail entries for user logons/logoffs
USER_AUDIT_OBJECT Audit trail records for statements concerning objects, specifically: table,
cluster, view, index, sequence, [public] database link, [public] synonym, procedure, trigger,
rollback segment, tablespace, role, user
USER_AUDIT_STATEMENT Audit trail records concerning grant, revoke, audit, noaudit and alter
system
USER_AUDIT_TRAIL Audit trail entries relevant to the user
USER_CATALOG Tables, Views, Synonyms and Sequences owned by the user
USER_CLUSTERS Descriptions of user’s own clusters
USER_CLU_COLUMNS Mapping of table columns to cluster columns
USER_COL_COMMENTS Comments on columns of user’s tables and views
USER_COL_GRANTS Grants on columns for which the user is the owner, grantor or grantee
USER_COL_GRANTS_MADE All grants on columns of objects owned by the user
USER_COL_GRANTS_RECD Grants on columns for which the user is the grantee
USER_COL_PRIVS Grants on columns for which the user is the owner, grantor or grantee
USER_COL_PRIVS_MADE All grants on columns of objects owned by the user
USER_COL_PRIVS_RECD Grants on columns for which the user is the grantee
USER_CONSTRAINTS Constraint definitions on user’s own tables
USER_CONS_COLUMNS Information about accessible columns in constraint definitions
USER_CROSS_REFS Cross references for user’s views and synonyms
USER_DB_LINKS Database links owned by the user
USER_DEPENDENCIES Dependencies to and from a users objects
USER_ERRORS Current errors on stored objects owned by the user
USER_EXTENTS Extents comprising segments owned by the user
USER_FREE_SPACE Free extents in tablespaces accessible to the user
USER_INDEXES Description of the user’s own indexes
USER_IND_COLUMNS COLUMNs comprising user’s INDEXes or on user’s TABLES
USER_JOBS All jobs owned by this user
USER_OBJECTS Objects owned by the user
USER_OBJECT_SIZE Sizes, in bytes, of various pl/sql objects
USER_OBJ_AUDIT_OPTS Auditing options for user’s own tables and views
USER_REFRESH All the refresh groups
USER_REFRESH_CHILDREN All the objects in refresh groups, where the user owns the refresh group
USER_RESOURCE_LIMITS Display resource limit of the user
USER_ROLE_PRIVS Roles granted to current user
USER_SEGMENTS Storage allocated for all database segments
USER_SEQUENCES Description of the user’s own SEQUENCEs
USER_SNAPSHOTS Snapshots the user can look at
USER_SNAPSHOT_LOGS All snapshot logs owned by the user
USER_SOURCE Source of stored objects accessible to the user
USER_SYNONYMS The user’s private synonyms
USER_SYS_PRIVS System privileges granted to current user
USER_TABLES Description of the user’s own tables
USER_TABLESPACES Description of accessible tablespaces
USER_TAB_AUDIT_OPTS Auditing options for user’s own tables and views
USER_TAB_COLUMNS Columns of user’s tables, views and clusters
USER_TAB_COMMENTS Comments on the tables and views owned by the user
USER_TAB_GRANTS Grants on objects for which the user is the owner, grantor or grantee
USER_TAB_GRANTS_MADE All grants on objects owned by the user
USER_TAB_GRANTS_RECD Grants on objects for which the user is the grantee
USER_TAB_PRIVS Grants on objects for which the user is the owner, grantor or grantee
USER_TAB_PRIVS_MADE All grants on objects owned by the user
USER_TAB_PRIVS_RECD Grants on objects for which the user is the grantee
USER_TRIGGERS Triggers owned by the user
USER_TRIGGER_COLS Column usage in user’s triggers
USER_TS_QUOTAS Tablespace quotas for the user
USER_USERS Information about the current user
USER_VIEWS Text of views owned by the user
AUDIT_ACTIONS Description table for audit trail action type codes. Maps action type
numbers to action type names
COLUMN_PRIVILEGES Grants on columns for which the user is the grantor, grantee, owner, or
an enabled role or PUBLIC is the grantee
DICTIONARY Description of data dictionary tables and views
DICT_COLUMNS Description of columns in data dictionary tables and views
GLOBAL_NAME global database name
INDEX_HISTOGRAM statistics on keys with repeat count
INDEX_STATS statistics on the b-tree
RESOURCE_COST Cost for each resource
ROLE_ROLE_PRIVS Roles which are granted to roles
ROLE_SYS_PRIVS System privileges granted to roles
ROLE_TAB_PRIVS Table privileges granted to roles
SESSION_PRIVS Privileges which the user currently has set
SESSION_ROLES Roles which the user currently has enabled.
TABLE_PRIVILEGES Grants on objects for which the user is the grantor, grantee, owner, or
an enabled role or PUBLIC is the grantee
ACCESSIBLE_COLUMNS Synonym for ALL_TAB_COLUMNS
ALL_COL_GRANTS Synonym for COLUMN_PRIVILEGES
ALL_JOBS Synonym for USER_JOBS
ALL_TAB_GRANTS Synonym for TABLE_PRIVILEGES
CAT Synonym for USER_CATALOG
CLU Synonym for USER_CLUSTERS
COLS Synonym for USER_TAB_COLUMNS
DBA_AUDIT_CONNECT Synonym for USER_AUDIT_CONNECT
DBA_AUDIT_RESOURCE Synonym for USER_AUDIT_RESOURCE
DBA_REFRESH_CHILDREN Synonym for USER_REFRESH_CHILDREN
DICT Synonym for DICTIONARY
IND Synonym for USER_INDEXES
OBJ Synonym for USER_OBJECTS
SEQ Synonym for USER_SEQUENCES
SM$VERSION Synonym for SM_$VERSION
SYN Synonym for USER_SYNONYMS
TABS Synonym for USER_TABLES
V$ACCESS Synonym for V_$ACCESS
V$ARCHIVE Synonym for V_$ARCHIVE
V$BACKUP Synonym for V_$BACKUP
V$BGPROCESS Synonym for V_$BGPROCESS
V$CIRCUIT Synonym for V_$CIRCUIT
V$COMPATIBILITY Synonym for V_$COMPATIBILITY
V$COMPATSEG Synonym for V_$COMPATSEG
V$CONTROLFILE Synonym for V_$CONTROLFILE
V$DATABASE Synonym for V_$DATABASE
V$DATAFILE Synonym for V_$DATAFILE
V$DBFILE Synonym for V_$DBFILE
V$DBLINK Synonym for V_$DBLINK
V$DB_OBJECT_CACHE Synonym for V_$DB_OBJECT_CACHE
V$DISPATCHER Synonym for V_$DISPATCHER
V$ENABLEDPRIVS Synonym for V_$ENABLEDPRIVS
V$FILESTAT Synonym for V_$FILESTAT
V$FIXED_TABLE Synonym for V_$FIXED_TABLE
V$LATCH Synonym for V_$LATCH
V$LATCHHOLDER Synonym for V_$LATCHHOLDER
V$LATCHNAME Synonym for V_$LATCHNAME
V$LIBRARYCACHE Synonym for V_$LIBRARYCACHE
V$LICENSE Synonym for V_$LICENSE
V$LOADCSTAT Synonym for V_$LOADCSTAT
V$LOADTSTAT Synonym for V_$LOADTSTAT
V$LOCK Synonym for V_$LOCK
V$LOG Synonym for V_$LOG
V$LOGFILE Synonym for V_$LOGFILE
V$LOGHIST Synonym for V_$LOGHIST
V$LOG_HISTORY Synonym for V_$LOG_HISTORY
V$MLS_PARAMETERS Synonym for V_$MLS_PARAMETERS
V$MTS Synonym for V_$MTS
V$NLS_PARAMETERS Synonym for V_$NLS_PARAMETERS
V$NLS_VALID_VALUES Synonym for V_$NLS_VALID_VALUES
V$OPEN_CURSOR Synonym for V_$OPEN_CURSOR
V$OPTION Synonym for V_$OPTION
V$PARAMETER Synonym for V_$PARAMETER
V$PQ_SESSTAT Synonym for V_$PQ_SESSTAT
V$PQ_SLAVE Synonym for V_$PQ_SLAVE
V$PQ_SYSSTAT Synonym for V_$PQ_SYSSTAT
V$PROCESS Synonym for V_$PROCESS
V$QUEUE Synonym for V_$QUEUE
V$RECOVERY_LOG Synonym for V_$RECOVERY_LOG
V$RECOVER_FILE Synonym for V_$RECOVER_FILE
V$REQDIST Synonym for V_$REQDIST
V$RESOURCE Synonym for V_$RESOURCE
V$ROLLNAME Synonym for V_$ROLLNAME
V$ROLLSTAT Synonym for V_$ROLLSTAT
V$ROWCACHE Synonym for V_$ROWCACHE
V$SESSION Synonym for V_$SESSION
V$SESSION_CURSOR_CACHE Synonym for V_$SESSION_CURSOR_CACHE
V$SESSION_EVENT Synonym for V_$SESSION_EVENT
V$SESSION_WAIT Synonym for V_$SESSION_WAIT
V$SESSTAT Synonym for V_$SESSTAT
V$SESS_IO Synonym for V_$SESS_IO
V$SGA Synonym for V_$SGA
V$SGASTAT Synonym for V_$SGASTAT
V$SHARED_SERVER Synonym for V_$SHARED_SERVER
V$SQLAREA Synonym for V_$SQLAREA
V$STATNAME Synonym for V_$STATNAME
V$SYSSTAT Synonym for V_$SYSSTAT
V$SYSTEM_CURSOR_CACHE Synonym for V_$SYSTEM_CURSOR_CACHE
V$SYSTEM_EVENT Synonym for V_$SYSTEM_EVENT
V$THREAD Synonym for V_$THREAD
V$TIMER Synonym for V_$TIMER
V$TRANSACTION Synonym for V_$TRANSACTION
V$TYPE_SIZE Synonym for V_$TYPE_SIZE
V$VERSION Synonym for V_$VERSION
V$WAITSTAT Synonym for V_$WAITSTAT
V$_LOCK Synonym for V_$_LOCK
在Oracle 中实现数据库的复制
在Internet 上运作数据库经常会有这样的需求:把遍布全国各城市相似的数据库应用统一起来,一个节
点的数据改变不仅体现在本地,还反映到远端。复制技术给用户提供了一种快速访问共享数据的办法。
一、实现数据库复制的前提条件
1、数据库支持高级复制功能
您可以用system 身份登录数据库,查看v$option 视图,如果其中Advanced replication 为TRUE,则支
持高级复制功能;否则不支持。
2、数据库初始化参数要求
①、db_domain = test.com.cn
指明数据库的域名(默认的是WORLD),这里可以用您公司的域名。
②、global_names = true
它要求数据库链接(database link)和被连接的数据库名称一致。
现在全局数据库名:db_name+”.”+db_domain
③、有跟数据库job 执行有关的参数
job_queue_processes = 1
job_queue_interval = 60
distributed_transactions = 10
open_links = 4
第一行定义SNP 进程的启动个数为n。系统缺省值为0,正常定义范围为0~36,根据任务的多少,可以配
置不同的数值。
第二行定义系统每隔N 秒唤醒该进程一次。系统缺省值为60 秒,正常范围为1~3600 秒。事实上,该进
程执行完当前任务后,就进入睡眠状态,睡眠一段时间后,由系统的总控负责将其唤醒。
如果修改了以上这几个参数,需要重新启动数据库以使参数生效。
二、实现数据库同步复制的步骤
假设在Internet 上我们有两个数据库:一个叫深圳(shenzhen),一个叫北京(beijing)。
具体配置见下表:
数据库名 shenzhen beijing
数据库域名 test.com.cn test.com.cn
数据库sid 号 shenzhen beijing
Listener 端口号 1521 1521
服务器ip 地址 10.1.1.100 10.1.1.200
1、确认两台数据库之间可以互相访问,在tnsnames.ora 里设置数据库连接字符串。
①、例如:深圳这边的数据库连接字符串是以下的格式
beijing =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.1.1.200)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = beijing)
)
)
运行$tnsping beijing
出现以下提示符:
Attempting to contact (ADDRESS=(PROTOCOL=TCP)(HOST=10.1.1.200)(PORT=1521))
OK(n 毫秒)
表明深圳数据库可以访问北京数据库。
②、在北京那边也同样配置,确认$tnsping shenzhen 是通的。
2、改数据库全局名称,建公共的数据库链接。
①、用system身份登录shenzhen 数据库
SQL>alter database rename global_name to shenzhen.test.com.cn;
用system身份登录beijing数据库:
SQL>alter database rename global_name to beijing.test.com.cn;
②、用system身份登录shenzhen 数据库
SQL>create public database link beijing.test.com.cn using ‘beijing’;
测试数据库全局名称和公共的数据库链接
SQL>select * from global_name@beijing.test.com.cn;
返回结果为beijing.test.com.cn 就对了。
用system身份登录beijing数据库:
SQL>create public database link shenzhen.test.com.cn using ‘shenzhen’;
测试数据库全局名称和公共的数据库链接
SQL>select * from global_name@shenzhen.test.com.cn;
返回结果为shenzhen.test.com.cn 就对了。
3、建立管理数据库复制的用户repadmin,并赋权。
①、用system身份登录shenzhen 数据库
SQL>create user repadmin identified by repadmin default tablespace users temporary tablespace
temp;
SQL>execute dbms_defer_sys.register_propagator(‘repadmin’);
SQL>grant execute any procedure to repadmin;
SQL>execute dbms_repcat_admin.grant_admin_any_repgroup(‘repadmin’);
SQL>grant comment any table to repadmin;
SQL>grant lock any table to repadmin;
②、同样用system 身份登录beijing 数据库,运行以上的命令,管理数据库复制的用户repadmin,并赋
权。
说明:repadmin用户名和密_____码可以根据用户的需求***命名。
4、在数据库复制的用户repadmin 下创建私有的数据库链接。
①、用repadmin 身份登录shenzhen 数据库
SQL>create database link beijing.test.com.cn connect to repadmin identified by repadmin;
测试这个私有的数据库链接:
SQL>select * from global_name@beijing.test.com.cn;
返回结果为beijing.test.com.cn 就对了。
②、用repadmin 身份登录beijing数据库
SQL>create database link shenzhen.test.com.cn connect to repadmin identified by repadmin;
测试这个私有的数据库链接
SQL>select * from global_name@shenzhen.test.com.cn;
返回结果为shenzhen.test.com.cn 就对了。
5、创建或选择实现数据库复制的用户和对象,给用户赋权,数据库对象必须有主关键字。
假设我们用ORACLE 里举例用的scott 用户,dept 表。
①、用internal 身份登录shenzhen 数据库,创建scott用户并赋权
SQL>create user scott identified by tiger default tablespace users temporary tablespace temp;
SQL>grant connect, resource to scott;
SQL>grant execute on sys.dbms_defer to scott;
②、用scott 身份登录shenzhen 数据库,创建表dept
SQL>create table dept
(deptno number(2) primary key,
dname varchar2(14),
loc varchar2(13) );
③、如果数据库对象没有主关键字,可以运行以下SQL 命令添加:
SQL>alter table dept add (constraint dept_deptno_pk primary key (deptno));
④、在shenzhen 数据库scott 用户下创建主关键字的序列号,范围避免和beijing 的冲突。
SQL> create sequence dept_no increment by 1 start with 1 maxvalue 44 cycle nocache;
(说明:maxvalue 44 可以根据应用程序及表结构主关键字定义的位数需要而定)
⑤、在shenzhen 数据库scott 用户下插入初始化数据
SQL>insert into dept values (dept_no.nextval,’accounting’,’new york’);
SQL>insert into dept values (dept_no.nextval,’research’,’dallas’);
SQL>commit;
⑥、在beijing 数据库那边同样运行以上①,②,③
⑦、在beijing 数据库scott 用户下创建主关键字的序列号,范围避免和shenzhen 的冲突。
SQL> create sequence dept_no increment by 1 start with 45 maxvalue 99 cycle nocache;
⑧、在beijing 数据库scott 用户下插入初始化数据
SQL>insert into dept values (dept_no.nextval,’sales’,’chicago’);
SQL>insert into dept values (dept_no.nextval,’operations’,’boston’);
SQL>commit;
6、创建要复制的组scott_mg,加入数据库对象,产生对象的复制支持
①、用repadmin 身份登录shenzhen 数据库,创建主复制组scott_mg
SQL> execute dbms_repcat.create_master_repgroup(‘scott_mg’);
说明:scott_mg 组名可以根据用户的需求***命名。
②、在复制组scott_mg 里加入数据库对象
SQL>execute dbms_repcat.create_master_repobject(sname=>’scott’,oname=>’dept’,
type=>’table’,use_existing_object=>true,gname=>’scott_mg’);
参数说明:
sname 实现数据库复制的用户名称
oname 实现数据库复制的数据库对象名称
(表名长度在27 个字节内,程序包名长度在24个字节内)
type 实现数据库复制的数据库对象类别
(支持的类别:表,索引,同义词,触发器,视图,过程,函数,程序包,程序包体)
use_existing_object true 表示用主复制节点已经存在的数据库对象
gname 主复制组名
③、对数据库对象产生复制支持
SQL>execute dbms_repcat.generate_replication_support(‘scott’,’dept’,’table’);
(说明:产生支持scott 用户下dept 表复制的数据库触发器和程序包)
④、确认复制的组和对象已经加入数据库的数据字典
SQL>select gname, master, status from dba_repgroup;
SQL>select * from dba_repobject;
7、创建主复制____节点
①、用repadmin 身份登录shenzhen 数据库,创建主复制节点
SQL>execute dbms_repcat.add_master_database
(gname=>’scott_mg’,master=>’beijing.test.com.cn’,use_existing_objects=>true,
copy_rows=>false, propagation_mode => ‘asynchronous’);
参数说明:
gname 主复制组名
master 加入主复制节点的另一个数据库
use_existing_object true 表示用主复制节点已经存在的数据库对象
copy_rows false 表示第一次开始复制时不用和主复制节点保持一致
propagation_mode 异步地执行
②、确认复制的任务队列已经加入数据库的数据字典
SQL>select * from user_jobs;
8、使同步组的状态由停顿(quiesced )改为正常(normal)
①、用repadmin 身份登录shenzhen 数据库,运行以下命令
SQL> execute dbms_repcat.resume_master_activity(‘scott_mg’,false);
②、确认同步组的状态为正常(normal)
SQL> select gname, master, status from dba_repgroup;
③、如果这个①命令不能使同步组的状态为正常(normal),可能有一些停顿的复制,运行以下命令再试试
(建议在紧急的时候才用):
SQL> execute dbms_repcat.resume_master_activity(‘scott_mg’,true);
9、创建复制数据库的时间表,我们假设用固定的时间表:10 分钟复制一次。
①、用repadmin 身份登录shenzhen 数据库,运行以下命令
SQL>begin
dbms_defer_sys.schedule_push (
destination => ‘beijing.test.com.cn’,
interval => ‘sysdate + 10/1440’,
next_date => sysdate);
end;
/
SQL>begin
dbms_defer_sys.schedule_purge (
next_date => sysdate,
interval => ‘sysdate + 10/1440’,
delay_seconds => 0,
rollback_segment => ”);
end;
/
②、用repadmin 身份登录beijing数据库,运行以下命令
SQL>begin
dbms_defer_sys.schedule_push (
destination => ‘ shenzhen.test.com.cn ‘,
interval => ‘sysdate + 10 / 1440’,
next_date => sysdate);
end;
/
SQL>begin
dbms_defer_sys.schedule_purge (
next_date => sysdate,
interval => ‘sysdate + 10/1440’,
delay_seconds => 0,
rollback_segment => ”);
end;
/
10、添加或修改两边数据库的记录,跟踪复制过程
如果你想立刻看到添加或修改后数据库的记录的变化,可以在两边repadmin 用户下找到push 的
job_number,然后运行:
SQL>exec dbms_job.run(job_number);
三、异常情况的处理
1、检查复制工作正常否,可以在repadmin 用户下查询user_jobs
SQL>select job,this_date,next_date,what, broken from user_jobs;
正常的状态有两种:
任务闲——this_date 为空,next_date 为当前时间后的一个时间值
任务忙——this_date 不为空,next_date 为当前时间后的一个时间值
异常状态也有两种:
任务死锁——next_date 为当前时间前的一个时间值
任务死锁——next_date 为非常大的一个时间值,例如:4001-01-01
这可能因为网络中断照成的死锁
解除死锁的办法:
$ps –ef|grep orale
找到死锁的刷新快照的进程号ora_snp*,用kill –9 命令删除此进程
然后进入repadmin 用户SQL>操作符下,运行命令:
SQL>exec dbms_job.run(job_number);
说明:job_number 为用select job,this_date,next_date,what from user_jobs;命令查出的job 编号。
2、增加或减少复制组的复制对象
①、停止主数据库节点的复制动作,使同步组的状态由正常(normal)改为停顿(quiesced )
用repadmin 身份登录shenzhen数据库,运行以下命令
SQL>execute dbms_repcat.suspend_master_activity (gname => ‘scott_mg’);
②、在复制组scott_mg 里加入数据库对象,保证数据库对象必须有主关键字。
SQL>execute dbms_repcat.create_master_repobject(sname=>’scott’,oname=>’emp’,
type=>’table’,use_existing_object=>true,gname=>’scott_mg’);
对加入的数据库对象产生复制支持
SQL>execute dbms_repcat.generate_replication_support(‘scott’,’emp’,’table’);
③、在复制组scott_mg 里删除数据库对象。
SQL>execute dbms_repcat.drop_master_repobject (‘scott’,’dept’,’table’);
④、重新使同步组的状态由停顿(quiesced )改为正常(normal)。
SQL> execute dbms_repcat.resume_master_activity(‘scott_mg’,false);
SQL*PLUS 环境输入‘&字符‘的方法
我们知道在SQL*PLUS默认环境里会把‘&字符‘当成变量来处理.
有些时候我们也需要在SQL>的符号下输入‘&字符‘, 只需要改变SQL*PLUS 下一个环境变量define 即可.
SQL> set define off;
是把默认的&绑定变量的功能取消, 可以把‘&字符‘当成普通字符处理
SQL> set define on;
打开&绑定变量的功能, &后面的字符串当变量使用.
SQL> show define;
查看当前SQL*PLUS 的define状态
举例说明:
—————————————————————
SQL> CREATE TABLE TEST3 (
ID NUMBER (2) PRIMARY KEY,
NAME VARCHAR2 (20));
SQL> show define;
define “&” (hex 26)
SQL> insert into test3 values(1,’sgs&a&n’);
Enter value for a: abc
Enter value for n: 456
old 1: insert into test3 values(1,’sgs&a&n’)
new 1: insert into test3 values(1,’sgsabc456′)
1 row created.
SQL> commit;
Commit complete.
SQL> set define off;
SQL> insert into test3 values(2,’sgs&a&n’);
1 row created.
SQL> commit;
Commit complete.
SQL> select * from test3;
ID NAME
— ——————–
1 sgsabc456
2 sgs&a&n
简说创建用户
SQL>create user dbuser identified by oracle default tablespace data temporary tablespace temp
quota unlimited on data quota 0 on system quota 0 on tools quota 0 on users;
SQL>grant connect to dbuser;
SQL>grant create procedure to dbuser; #这些权限足够用于开发及生产环境
SQL>grant select on dba_pending_transactions to dbuser; #二阶段提交过程中类似Tuxedo
的软件需要检索挂起交易的状态,所以必须得到对此视图的select权限,以sys 用户身份赋予
修改用户可使用alter user dbuser …
参考命令:
drop user dbuser cascade; #删除用户及其所有的数据对象
revoke connect from dbuser; #取消用户角色权限
相关系统表:
user(dba)_users
user(dba)_role_privs 角色权限
user(dba)_sys_privs 系统权限
user(dba)_tab_privs 对其他用户表操作的权限
user_ts_quotas 表空间限额
创建只读用户
假定数据库用户dbbrsr 需要对dbuser的表emp 拥有select 权力
connect dbuser
grant select on emp to dbbrsr
connect dbbrsr
create synonym emp for dbuser.emp;
这样,dbbrsr 就能象使用自己的表一样对dbuser 的表执行select 操作
简说Oracle 启动及关闭数据库实例
oracle 用户,dbstart 和dbshut 启动及关闭/var/opt/oracle/oratab 或/etc/oratab 中设定的数据库实
例,dbstart 采用normal 方式,dbshut 采用immediate 方式。
或者使用手工方式
sqlplus “/ as sysdba”
启动
normal
SQL>startup
mount
SQL>startup mount; #启动实例进程,载入数据库文件,允许DBA权限的某些操作,但禁止对数据库文
件的一般性操作
SQL>完成某些操作
SQL>alter database open;
nomount
SQL>startup nomount; #启动实例进程,但不允许访问数据库,常用于创建数据库、介质恢复或创建
controlfile
SQL>完成某些操作
SQL>alter database open;
关闭
normal
SQL>shutdown 或SQL>shutdown transactional; #等待每个连接交易完成后,切断连接,再关闭数据库
immediate
SQL>shutdown immediate; #立刻中止每个连接,交易回滚
abort
SQL>shutdown abort; #立刻关闭数据库,不保证交易完整性,在下一次启动打开数据库文件时会进行介
质恢复
简说Oracle 数据库导出(exp)/导入(imp)
exp
将数据库内的各对象以二进制方式下载成dmp 文件,方便数据迁移。
buffer:下载数据缓冲区,以字节为单位,缺省依赖操作系统
consistent:下载期间所涉及的数据保持read only,缺省为n
direct:使用直通方式 ,缺省为n
feeback:显示处理记录条数,缺省为0,即不显示
file:输出文件,缺省为expdat.dmp
filesize:输出文件大小,缺省为操作系统最大值
indexes:是否下载索引,缺省为n,这是指索引的定义而非数据,exp 不下载索引数据
log:log 文件,缺省为无,在标准输出显示
owner:指明下载的用户名
query:选择记录的一个子集
rows:是否下载表记录
tables:输出的表名列表
导出整个实例
exp dbuser/oracle file=oradb.dmp log=oradb.log full=y consistent=y direct=y
user 应具有dba权限
导出某个用户所有对象
exp dbuser/oracle file=dbuser.dmp log=dbuser.log owner=dbuser buffer=4096000 feedback=10000
导出一张或几张表
exp dbuser/oracle file=dbuser.dmp log=dbuser.log tables=table1,table2 buffer=4096000
feedback=10000
导出某张表的部分数据
exp dbuser/oracle file=dbuser.dmp log=dbuser.log tables=table1 buffer=4096000 feedback=10000
query=\”where col1=\’…\’ and col2 \<…\”
不可用于嵌套表
以多个固定大小文件方式导出某张表
exp dbuser/oracle file=1.dmp,2.dmp,3.dmp,… filesize=1000m tables=emp buffer=4096000
feedback=10000
这种做法通常用在:表数据量较大,单个dump文件可能会超出文件系统的限制
直通路径方式
direct=y,取代buffer 选项,query 选项不可用
有利于提高下载速度
consistent 选项
自export 启动后,consistent=y 冻结来自其它会话的对export 操作的数据对象的更新,这样可以保证
dump 结果的一致性。但这个过程不能太长,以免回滚段和联机日志消耗完
imp
将exp 下载的dmp文件上载到数据库内。
buffer:上载数据缓冲区,以字节为单位,缺省依赖操作系统
commit:上载数据缓冲区中的记录上载后是否执行提交
feeback:显示处理记录条数,缺省为0,即不显示
file:输入文件,缺省为expdat.dmp
filesize:输入文件大小,缺省为操作系统最大值
fromuser:指明来源用户方
ignore:是否忽略对象创建错误,缺省为n,在上载前对象已被建立往往是一个正常现象,所以此选项建
议设为y
indexes:是否上载索引,缺省为n,这是指索引的定义而非数据,如果上载时索引已建立,此选项即使为
n 也无效,imp 自动更新索引数据
log:log 文件,缺省为无,在标准输出显示
rows:是否上载表记录
tables:输入的表名列表
touser:指明目的用户方
导入整_____个实例
imp dbuser/oracle file=oradb.dmp log=oradb.log full=y buffer=4096000 commit=y ignore=y
feedback=10000
导入某个用户所有对象
imp dbuser/oracle file=dbuser.dmp log=dbuser.log fromuser=dbuser touser=dbuser2 buffer=2048000
commit=y ignore=y feedback=10000
导入一张或几张表
imp dbuser2/oracle file=user.dmp log=user.log tables=table1,table2 fromuser=dbuser
touser=dbuser2 buffer=2048000 commit=y ignore=y feedback=10000
以多个固定大小文件方式导入某张表
imp dbuser/oracle file=\(1.dmp,2.dmp,3.dmp,…\) filesize=1000m tables=emp fromuser=dbuser
touser=dbuser2 buffer=4096000 commit=y ignore=y feedback=10000
实例:Oracle 导出EXCEL 文件
FILENAME:=’文件名.xls’;
FHND:=TEXT_IO.FOPEN(FILENAME,’W’);
LINE_BUFF:='<TAB>’||’标题名称‘;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:=’列1<TAB>列2′;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
FOR RD IN TD LOOP
LINE_BUFF:=’值1’||'<TAB>’||’值2′;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
CNT:=CNT+1;
SYNCHRONIZE;
END LOOP;
TEXT_IO.FCLOSE(FHND);
注:<TAB>为按一下键盘上的TAB 键。
实例:Oracle 导出HTM文件
FILENAME:=’文件名.htm’;
FHND:=TEXT_IO.FOPEN(FILENAME,’W’);
LINE_BUFF:='<HTML><HEAD><TITLE>标题名称</TITLE></HEAD>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:='<BODY><STYLE>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:=’.tdtitle{font-family: “宋体“;color: #ffff11;font-size: 14px;}’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:=’.smtitle{font-family: “宋体“;color: #0000ff;font-size: 16px;}’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:=’.toptitle{font-family: “宋体“;color: #0000ff;font-size: 18px;}’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:=’.bigtitle{font-family: “隶书“;color: #0000ff;font-size: 24px;}’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:=’td{color: #000000;font-size: 12px;}’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:='</STYLE>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:='<CENTER><font class=smtitle>标题名称</font></CENTER>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:='<BR><table border=1 cellspacing=0 cellpadding=0>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
LINE_BUFF:='<tr><td>列1</td><td>列2</td></tr>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
FOR RD IN TD LOOP
LINE_BUFF:='<tr><td>’||’值1’||'</td><td>’
||'<tr><td>’||’值2’||'</td><tr>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
CNT:=CNT+1;
SYNCHRONIZE;
END LOOP;
LINE_BUFF:='</BODY></HTML>’;
TEXT_IO.PUT_LINE(FHND,LINE_BUFF);
TEXT_IO.FCLOSE(FHND);
查看数据库保留字
SELECT * FROM V$RESERVED_WORDS
查看数据库、实例、许可状态、数据库连接
SELECT * FROM V$DATABASE
SELECT * FROM V$INSTANCE
SELECT * FROM V$LICENSE
SELECT * FROM V$DBLINK
查看密码文件用户
SELECT * FROM V$PWFILE_USERS
查看资源限制
SELECT * FROM V$RESOURCE_LIMIT
查看数据库选项、对象参数
SELECT * FROM V$OPTION
SELECT * FROM SYS.ARGUMENT$
查看兼容性
SELECT * FROM V$COMPATIBILITY
查看数据库数据字典(表、视图、索引)
SELECT * FROM V$FIXED_TABLE
SELECT * FROM V$FIXED_VIEW_DEFINITION
SELECT * FROM V$INDEXED_FIXED_COLUMN
查看数据库NLS状态
SELECT * FROM SYS.PROPS$
查看表空间、控制、日志、数据文件及备份、读写状态
SELECT * FROM V$TABLESPACE
SELECT * FROM V$CONTORLFILE
SELECT * FROM V$LOGFILE
SELECT * FROM V$DATAFILE
SELECT * FROM V$BACKUP
SELECT * FROM V$FILESTAT
查看归档日志数、路径、进程
SELECT * FROM V$ARCHIVE_LOG
SELECT * FROM V$ARCHIVED_DEST
SELECT * FROM V$ARCHIVE_PROCESSES
查看回滚段名、状态
SELECT * FROM V$ROLLNAME
SELECT * FROM V$POLLSTAT
数据字典及某些字段意义
SELECT sum(decode(n.statistic#, 15, s.value,0)) UGA,
sum(decode(n.statistic#, 20, s.value,0))/1024||’K’ PGA,
sum(decode(n.statistic#, 180, s.value,0)) Sore_In_Member,
sum(decode(n.statistic#, 181, s.value,0)) Sore_In_Disk,
sum(decode(n.statistic#, 182, s.value,0)) Sore_Of_Row,
sum(decode(n.statistic#, 6, s.value,0)) User_Call,
sum(decode(n.statistic#, 5, s.value,0)) User_Rollback,
sum(decode(n.statistic#, 4, s.value,0)) User_Commit,
sum(decode(n.statistic#, 3, s.value,0)) Current_Opened_Cursor,
sum(decode(n.statistic#, 1, s.value,0)) Current_Logon,
sum(decode(n.statistic#, 9, s.value,0)) Session_Logical_Read ,
sum(decode(n.statistic#, 150, s.value,0)) Short_Table_Scans ,
sum(decode(n.statistic#, 151, s.value,0)) Long_Table_Scans
FROM V$SESSTAT s,V$STATNAME n
WHERE s.STATISTIC# = n.STATISTIC#;
select * from v$rollstat;
select * from v$sgastat;
select * from v$sysstat;
select * from V$PROCESS;
select * from V$THREAD;
select * from V$TIMER;
select * from V$OBJECT_DEPENDENCY;
select * from V$ROWCACHE;
SID:会话唯一标识
TS#:表空间唯一标识
FILE#:数据文件唯一标识
RFILE#:?
LATCT#:LATCH
PADDR;进程地址
SADDR:会话地址
SQL_ADDRESS :SQL语句地址
PREV_SQL_ADDR;前一个SQL语句地址
KADDR:锁地址
ADDR:对象地址
LADDR:LATCH
转载请注明:IT运维空间 » linux » Oracle DBA常用SQL
你可能喜欢:
-
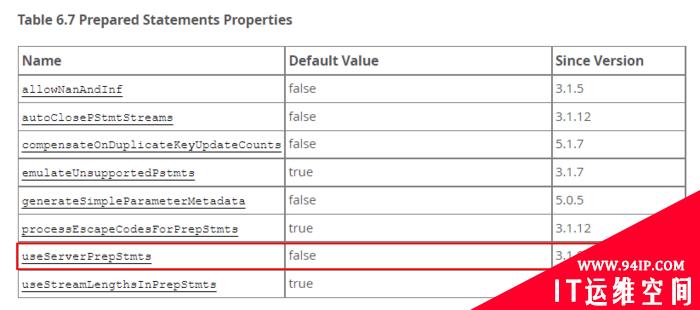
MySQL与JDBC之间的SQL预编译技术讲解
-

详解MySQL Shell 运行 SQL 的两种内置方法
-

mysql错误:java.sql.SQLException: The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone.
-

ORACLE SQL TUNING ADVISOR 使用方法
-

通用的关于sql注入的绕过技巧(利用mysql的特性)
-

mysql 生成UUID() 即 ORACLE 中的guid()函数
-

执行多条SQL语句,实现数据库事务。(Oracle数据库)
-
Oracle DBA常用SQL
-

MySQL架构优化实战系列4:SQL优化步骤与常用管理命令
-

探究MySQL中SQL查询的成本




发表评论