

 Written by RuilongDeng, AnNie
Written by RuilongDeng, AnNie
Key Points Overview
1. Operations Idea:Specifythe operations objects, start from the service life cycle, divide the stages, extract the key points, build the operations scenarios, and precipitate the operations platforms. 2. Reliability System:It advocates solving problems from the “Trinity” system, and fault prevention is far more effective than fault emergency. By doingstandardized construction, container deployment, service governance, change management, active-activearchitecture, anti-architecture fission, etc., the MTBF time is extended to meet the demand of high reliability. If the prevention doesn’t work,then embrace the fault handling methodology, and use emergency plan, monitoring and observability tools, and mechanism to maximally shorten the MTTR time, etc. 3. Transformation Exploration:Cloud native has a great impact on SRE. It is necessary to improve the role cognition, improve the ability model, attach importance to make operations’ workto be service-oriented, use engineering methods to completely define and reshape operations, deeply embrace open source, strive for common operations.
Technology Overview
ZUOYEBANGisaChinese high-tech company, its business can be divided into several scenes. There are tools, e-commerce, live broadcast, and the intelligent hardware scenes. Behind these business scenes, the number of services has reached thousands, the NS has reached hundreds, the domain names has reached thousands, and instance nodes has reached tens of thousands. Additionally, programming languages are also blooming everywhere, nearly to ten types, but the main ones are Golang and PHP. Behind such a large-scale business, we have two major technology bases. One is the cloud native architecture represented by container technology and service governance, and the other is the active-active deployment architecture connecting public clouds in the same area.

Team Model
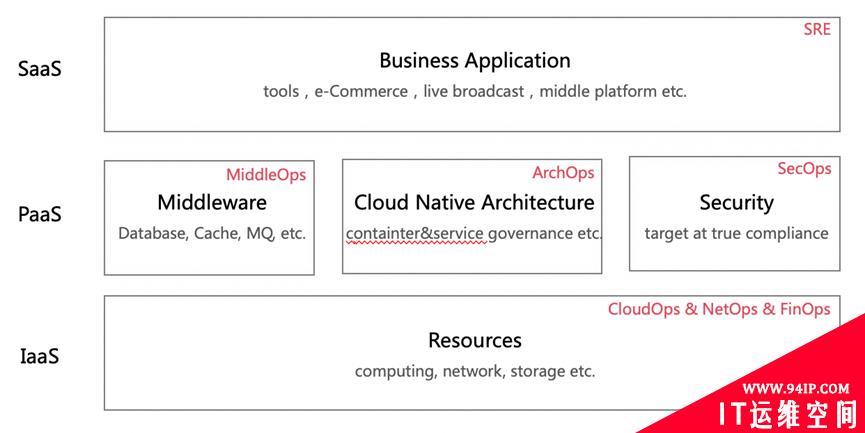
How to efficiently do operations for such a large-scale business? Let’s take a look at the team model of our basic technology. From the bottom to the top, it is divided into IaaS, PaaS and SaaS types. The IaaS is mainly responsible for providing computing, network, storage and other resources to the upper service; The PaaS is divided into three parts, including middleware services based on data storage and message queue, cloud native architecture services based on container technology and service governance, and security services targeted at true compliance; The top is business applications, including tools, e-commerce, live broadcast, and other middle platforms. Operations roles naturally arise when the applications become more complicated. The lowest level IaaS derives CloudOps, NetOps and FinOps, middleware services derive MiddleOps, cloud native architecture derives ArchOps, security services derive SecOps, and business applications derive SRE.
Operations Practice
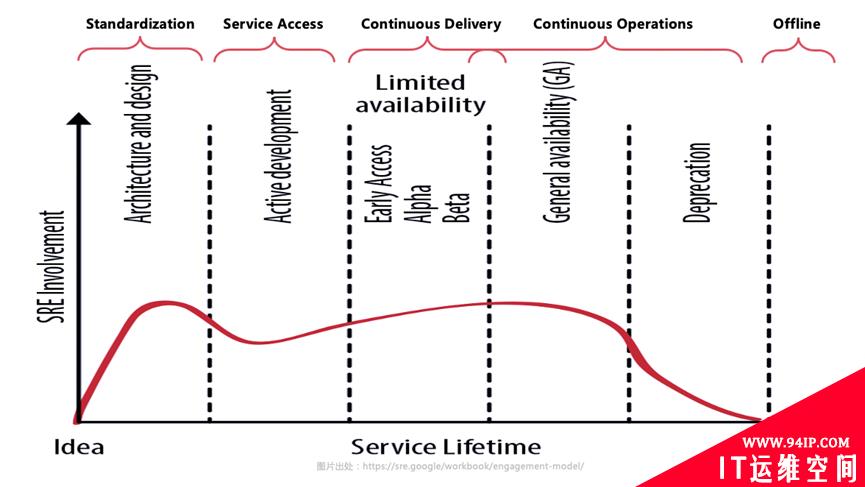
Google SRE divides the service life cycle into five stages. It believes that the service is born at the moment when the idea is determined, then the architecture design is beginning, then the development is active, then the gray scale / full scale release is carried out, and finally the service is abandoned, ending its life. From the perspective of operations, standardization construction is kick-off in the architecture design stage; In the development stage, service access process is open; In the gray/full scale release stage, continuous delivery and continuous operations keep going; Finally, the service goes offline. How do we get involved in operations in several stages of the service life cycle?
Standardization Construction
The key ideas are as follows: 1. Standards Pre-Comply:Mandatorily implant operations standards and architecture standards in business applications, strive for common operations, unify architecture, and try best to make everything ready when opening box, and strive to block large-scale reliability problems through standard architectures and operations. 2. Architecture Re-Modeling:Practice the ideaof cloud native architecture, focus on business services, focus on value and agile delivery, smooth the differences of IaaS resources through container technology, and smooth the differences of multi clouds environment through service governance. Key practices are as follows: 1. To Operations: Services Unification,mainly for the removal of mixed deployment and domain name splitting. In the virtual machine era, in order to improve resource utilization, a large number of services are mixed together, which brings disastrous troubles to SRE. For example, in the mixed deployment state, ODP services interfere with each other, so it is impossible to accurately control deployment and control permissions according to the service dimension, and it is impossible to conduct accurate capacity evaluation and so on. Domain name is split from the WWW public one, so that each business has an independent domain name, facilitating north-south traffic scheduling and container migration. Deployment Unification,mainly defines the deployment environment specification, divides the deployment process into three smoke impact production environments: tips (pre deploy), small (gray scale) and online (full traffic), and requires them to be code isomorphic, configuration isomorphic, routing isomorphic and environment isomorphic. If the CD platform is used for deployment, the code isomorphism is easy to handle, while the configuration isomorphism is slightly complicated. We use the characteristics of service discovery to hide the details of configuration heterogeneity behind the service discovery and make it transparent to the business. Network Unification,mainly refers to the unification of fiber lines access points to IDC POP points, the unification of physical fiber lines to transmission lines, the normalization of network detection protocols to BFD protocols, and the normalization of QoS control to CPE. Machine Model Unification,mainly converges to the mainstream universal model, and the differences between the models are smoothed by the deployment of containers. At the same time, the SaaS business is not allowed to touch the machine, so that it can be true compliance. 2. To Architecture: Service Discovery Unification,mainly normalizes East-West service discovery to SVC and North-South service discovery to DNS. In the early years, BNS was used for service discovery. Later, ZnS was evolved to support multi clouds deployment. Both of them belong to the central architecture. Later, they evolved to the current SVC mode, changing the previous style from the central architecture mode to the autonomous service discovery mode within the cluster, so as to avoid mutual influence between the clouds. FrameworkUnification, mainly converges the PHP framework to ODP, and the Go framework is converged to the ZGIN framework. Middleware Unification, is to build key components and services by ourselves and make their types unified, such as deprecating MemCache and NMQ. Big data components are purchased from public cloud PaaS services. Communication Unification, mainly use unified standard communication protocols, such as HTTP, TCP, etc., and deprecates business customized protocols.
Service Access
In the service access stage, the main idea is to let the business users do multiple-choice questions instead of filling in the blanks. At the same time, we will instill the concept of standardization into the users. Only by following our rules can they enjoy the full operations service when opening box.
Continuous Delivery
The concept of continuous delivery is slightly generalized. It covers all change delivery scenarios, including business changes and operations changes. Main ideas are as follows: 1. Embrace Methodology.For the direction of the change, the methodology in the industry is relatively mature. It is OK to copy them strictly according to the five military rules of the change. 2. Reshape the Change Plane.Introduce the main responsibility idea, clear the work boundary, change the co-operation mode, move the changes with business logic down to the business, and move the changes of operations attributes up to SRE. 3. Delivery Platform. Operations change is also a (global) variable that causes failure. It is better not to rely on the professionalism of people in the change method, but to apply military regulations / SOP into platforms, so that SRE can easily click and mutualbackup at low cost. Key practices are mainly reflected in R&D changes and SRE changes. 1. R&D Changes. There are two modes of code change: agile release and waterfall release. Agile release is mainly for ToC business, while waterfall release is slightly more traditional and mainly for ToB business. They often need to save a whole week’s code change, and then release them once in a time window. They like to observe the gray environment for more time, and completely release to online environment after there is no problem. Configuration publishing integrates into the CD process. We reshape the work model from centralized configuration pushing to service granularity pushing. After the scheduledtask is released, the approval phase is introduced, and the quality is checked, then the scheduledtask is launched. Data storage changes are mainly delivered through the DBA order platform. 2. SRE Changes.It mainly includes machine delivery, node delivery, domain name delivery, EIP / LB delivery, service route delivery, capacity delivery, job delivery, emergency plan delivery, migration delivery, component delivery, non-standard delivery, etc. In addition to EIP / LB, which is multi cloud and heterogeneous, and non-standard delivery, we basically have the ability to deliver the work through order platform, the business people submit a delivery order in our system and SRE just focus on checking and approval. After the standardized construction, the quality of changes has improved greatly. However, with the rise of micro services, the frequency of operations has also increased unexpectedly. The good news is that the order platform has effectively improved the efficiency of operations delivery, and only a few SREs can hold down the voice of the whole business.
Continuous Operations
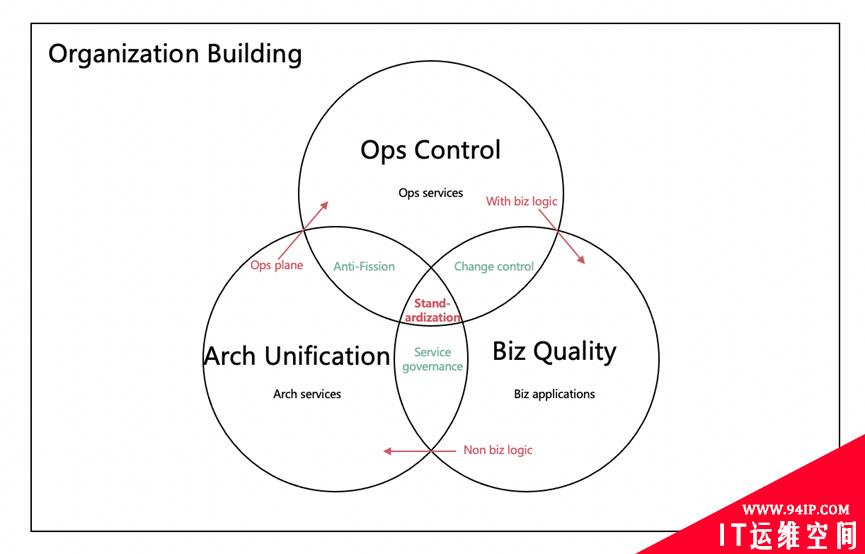
Reliability construction can be broadly divided into three parts: business quality, architecture unification and operations control. Of course, behind each dimension, they also have many corresponding services.
Generally, if a business wants to iterate faster, it actually needs a good service governance by the architecture; At the same time, if the business wants to iterate more stably, it actually needs elegant management and control of operations; Operations should also focus on the architecture measurement through technical means to prevent reliability problems caused by architecture fission; The architecture also needs more consideration, how to design and evolve will not lead operations to out of control. Additionally, whether it is business, operations, or architecture, if you want to extremely improve the reliability, three of them need standardization construction at the same time. Of course, these are not enough. Thinking from the bottom logic, let the business focus on value. We also need to change the new cooperation mode. From the perspective of operations, things with business logic are moved down to the business, such as configuration publishing, schedules task publishing, and business logic mixed by the access layer. From the business perspective, move the non-business logic things to the architecture, such as service discovery, unified authentication, traffic scheduling, etc. From the perspective of architecture, moving the ToC(operations) control plane up to the operations, such as capacity management and traffic scheduling, can’t let the business directly penetrate the operations control and directly hit our containers. Finally, in addition to the three, we have also have a powerful organization, which can ensure the above-mentioned things running well.
This is the “Trinity” reliability system of ZUOYEBANG, as shown in the figure below.
 After running in the above system, we naturally have such operations ideas.
1. Strengthen the Sense of Responsibility, clarify the responsibility of the service provider, return the business problems to the business team, return the operations problems to the operations team, and return the architecture problem to the architecture team.
2. Strengthen the Concept of the Platform,avoid repeated toils, and pay attention to the precipitation of sustainable operations ability. We believe that the platform is the most understandable and inheritable way.
3. Strengthen thePractice of Data Driving,establish multi-dimensional measurement platform, make the data analysis capability open, specify the responsibility for different problems, and make good use of TC organization power to drive the continuous optimization and evolution of the whole system.
After running in the above system, we naturally have such operations ideas.
1. Strengthen the Sense of Responsibility, clarify the responsibility of the service provider, return the business problems to the business team, return the operations problems to the operations team, and return the architecture problem to the architecture team.
2. Strengthen the Concept of the Platform,avoid repeated toils, and pay attention to the precipitation of sustainable operations ability. We believe that the platform is the most understandable and inheritable way.
3. Strengthen thePractice of Data Driving,establish multi-dimensional measurement platform, make the data analysis capability open, specify the responsibility for different problems, and make good use of TC organization power to drive the continuous optimization and evolution of the whole system.
Continuous Operations – Active-Active Architecture
The construction of active-active architecture is an old topic in the industry, and any large and medium-sized company will be involved in it. From the perspective of the industry, active-active architecture has a mature methodology, but lacks mature standard guidance. Many people are good at building such an active-active architecture from 0 to 1, but they often operate poorly and fail in the end. Here, we will talk about how we make difference from the operational view.
1. Solidify the Operations Capability,build a multi active information platform, precipitate operations data combining with the operations scenario, avoid repeated toils, make it sustainable and safely open ToC.
2. Build Observability for Cross Clouds,go deep into the business, find out the business code, configuration characteristics and service dependency behavior, and establish cross cloud observability capability and perceive the source & target details of cross cloud traffic using the CPE tuple data from fiber lines and the eBPF data from the kernel ConnTracks.
3. Disconnect Network Between Clouds,bravely moving forward into the industry no man’s land, and forcefully landing the network disconnection between the clouds, strive to solve the problems at the root, prevent the new non-standard problems or the fission of active-active architectures, and establish an active-active cloud measurement perspective to constrain the architecture behavior and guide the business update.
4. Approval from an Independent Perspective, introducing the chaos engineering idea, safely breaking the specification of its explosion radius, conducting the global single cloud fault injection drill from the online, and introducing the QA perspective, so that they can objectively accept the active-active capability from the user’s perspective.
Continuous Operations – Emergency Plan Platform
As mentioned above, the standardization construction, service access, continuous delivery and active-active architecture mainly focus on fault prevention and strive to extend MTBF time to achieve high reliability. If the prevention doesn’twork, we will try our best to shorten the MTTR time as more as possible.
After having such a good active-active architecture, how to enlarge its value, emergency plan is the best entry point. I have witnessed that many large and medium-sized companies have ambiguous definitions of the plan, and too many business logics are mixed, and finally the SRE dare not touch them. Therefore, it is necessary to redefine and remodel the emergency plan completely.
1. Definition of Emergency Plan:the emergency plan is a highly solidified complex operations aggregation, the bottom layer needs complex technical support, and finally needs to be abstracted into the ability of one button click solution. Don’t give the operator too much decision-making cost when encountering fault. Whoever is on duty will be able to operate without thinking.
2. Emergency Plan Boundary:the emergency plan should not have business logic. If there is, it should be moved down to the business layer for implementation.
3. Emergency Plan Reliability:the emergency plan belongs to the strong control plane, and its reliability needs to be higher than the reliability of the business applications. The data storage needs to be deployed in a modular multi master manner, and circular dependency is not allowed, especially the strong dependency on the portal account system.
4. Emergency Plan Orchestration: the emergency plan is not only a highly solidified complex operations aggregation, but also can have technical content. We introduce the idea of orchestration, arrange the atomic plan into scenario plan and global plan, and finally smooth out the differences between business plan, operations plan and user-customized plan for one button click solution. The customized plan is a technical highlight. It deposits customized commands, scripts, or other complex API calls into the git repo, then solidifies its operations methods through our job platform, and finally orchestrate them to the scene plan for leveling, so as to achieve the effect of one button click.
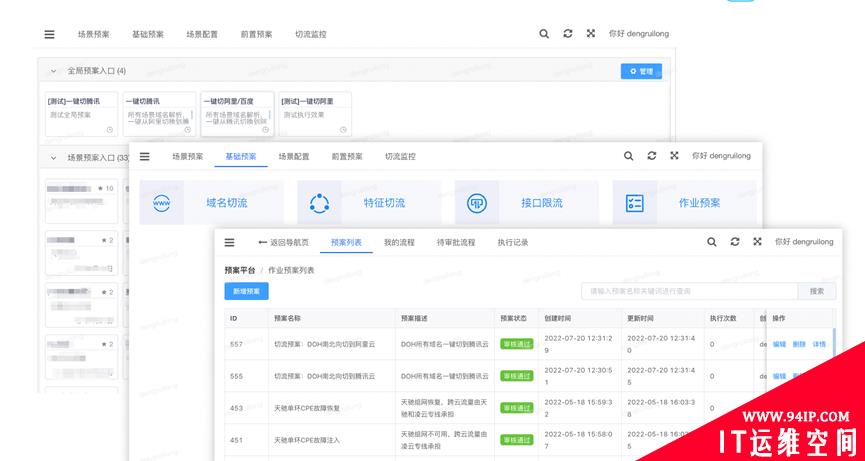
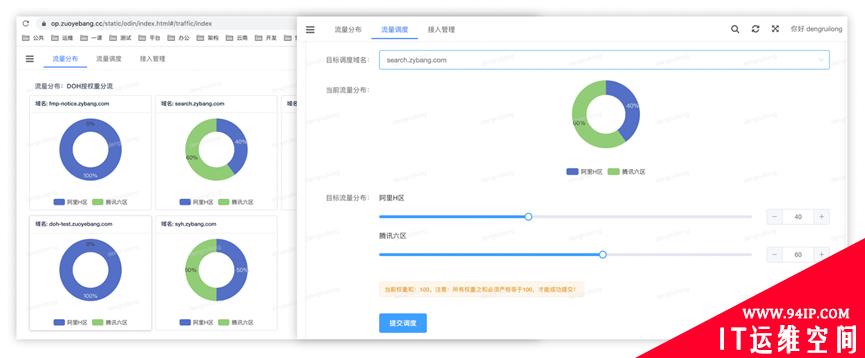
Continuous Operations – Traffic Scheduling
The SRE team focuses on the overall traffic scheduling in the north-south direction, the architecture team focuses on the long tail traffic scheduling in the east-west direction, and the business team focuses on the characteristic traffic scheduling, such as sharding traffic to different clouds by lesson. The scheduling object is the domain name. The scheduling starts from the public network entrance. Once the traffic enters the cloud, the single cloud is closed-loop, except for the underlying data storage, cross cloud SaaS traffic requests are not allowed. There are two scheduling methods, one is precise scheduling by DOH according to weight, and the other is non precise shunting scheduling by DNS according to resolution line.
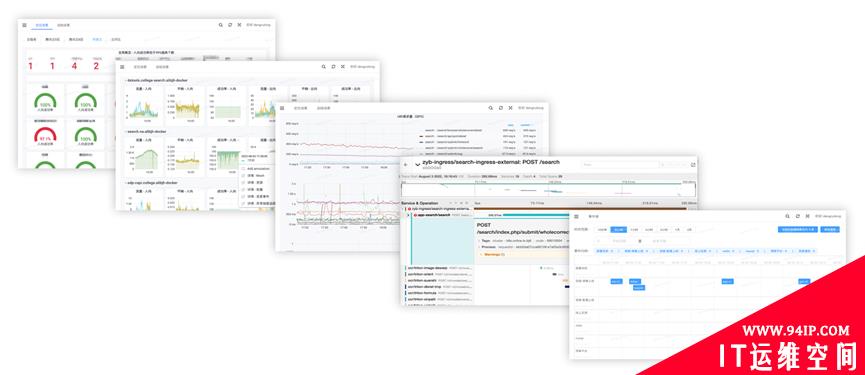
Continuous Operations – Scope & Analysis
The scope is biased towards the upper-level operations, and the problem analysis is biased towards the service observability. How can we combine the two into one for our use?
1. Build the Foundation.According to the three observable gold indicators, at the beginning of standardization, define the log specifications, and divide them into 8 types of logs for 4 scenarios, which were solidified into the application framework. Indicator collection mainly includes basic indicators, service indicators and business indicators. The tracing registration mainly generates or transparently transmits the trace ID at the portal, and uniformly registers the trace related information in the mesh sidecar, so that the service can be accessed at a low cost and can be used when opening box.
2. Set Up the Middle Platform.Instead of the traditional ELK cash burning solution, we cleverly built a multi-level data storage log solution with block storage and hot & cold data separation to support elegant log retrieval for more than half a year. Trace query system mainly embraces the open-source tool Jaeger. The monitoring platform mainly uses the Prometheus Victoria metric solution, combined with Grafana and OpenFalcon.
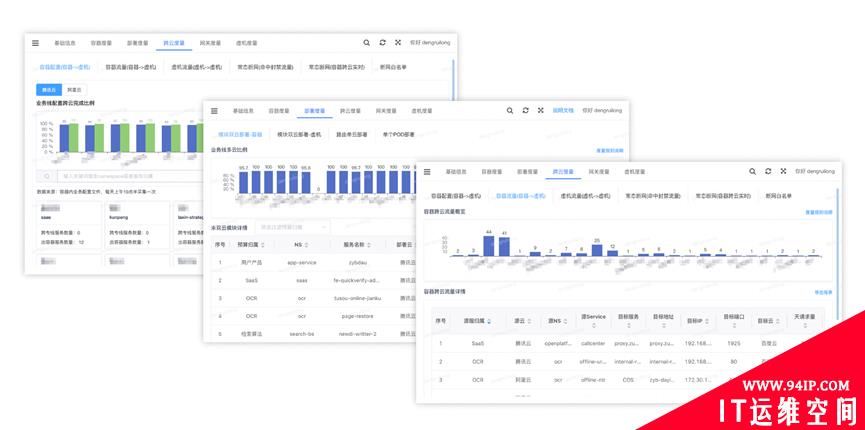
3. Create Scenarios.First establish a service perspective and let the business focus on service value. Second, establish an Ops view for fault scope and troubleshooting perspective, which enables fault scope at the top and troubleshooting at the bottom. At the same time, thousands of service monitoring or alarms are easy to lose focus if the eyebrows and whiskers are grasped. At this time, we should treat them differently and use the service level metadata to achieve convergence monitoring and alarm focus. Finally, the traffic light modeling and scoring are designed to build a global SRE perspective view.
The product is shown in the following figure. The first is to scope the whole business fault macroscopically. From the place where the light is red, which means the business services are not running well, you can drill down to the abnormal business’s service details. From the service details page, you can quickly drill down to the service Mesh incoming call details, outgoing call details, and the abnormal tracing details. You can also drill up to the whole business and service capacity and global change events.
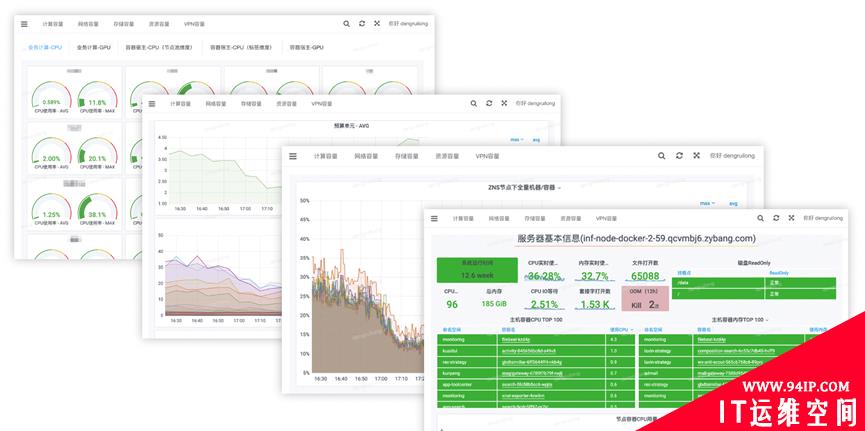
Continuous Operations – Capacity Monitoring
Capacity monitoring is similar to business monitoring. It covers CPU & GPU computing power, container host capacity, cloud host capacity, subnet IP capacity, fiber lines bandwidth capacity, VPN capacity, etc.
Continuous Operations – Others
At the alarming view, build a global general service alarming system, strive to play the role of the first jump of the fault, and make a quick query of the unrecovered and recent alarms to facilitate the support of the global decision-making. Permission operations mainly senses the changes of key permission points to prevent cross-border authorization and changes due to out-of-control Ops. Change control is mainly based on the five military regulations.
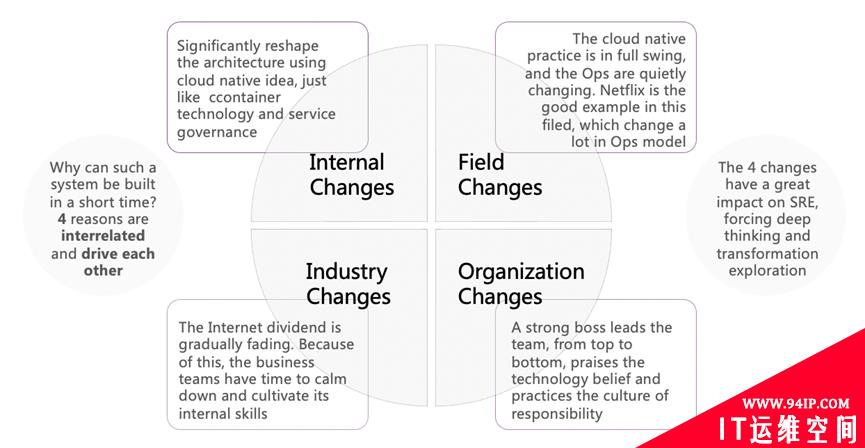
Environment Changes
Why can such a system be built in a short time (about 2+ years)? There are four major environmental changes, which are interrelated and drive each other.
1. Field Changes:The current cloud native technology is highly mature and the industry practice is in full swing.
2. Internal changes:The technical team is pragmatic, and the architecture is remodeled according to the physiological concept of Cloud Native, which has been tried and tested.
3. Industry Changes:The Internet dividend is gradually fading. Because of this, businesses team can have more time to calm down and cultivate their internal skills.
4. Organization changes:A strong boss leads the team, from the top to the bottom, from the outside to the inside, praising technology belief and practicing the culture of responsibility.
It is precisely because of these four changes that SRE has also brought unprecedented impact, forcing us to think deeply and explore transformation.
Transformation Thinking
Role Thinking
It can be seen from the team model that each operations role has its own main services. Only SRE is not the provider of business services, but depends on the business, infinitely extending and amplifying the value of the business. In the long run, it is easy to evolve into a horizontal support team, which greatly weakens the professionalism of SRE. Therefore, service-oriented operations are imminent. Returning to the original intention, let’s take a look at the definition of SRE. It is the acronym of site reliability engineering. The last word emphasizes engineering rather than engineers. The key point is to define and reconstruct the operations with engineering ideas and methods, so as to make the operations more automatic and more service-oriented, instead of hunting more engineers to dig holes repeatedly. The traditional operations tend to do thing passively. It is better if there is no problem. The style is carefully and rigorous, and focus on the process specification and SOP. The operations in the cloud native era puts more emphasis on building business data, measuring business risks, giving suggestions on standardized solutions, and taking the initiative. It is good at solidifying process specifications and SOPs into the architecture or platform. Finally, we should clearly understand the responsibilities of SRE role, that it is, to make the business iterate efficiently and make the business run reliably.
Ability Exploration
After having a new understanding of the role, let’s look at what kind of ability model SRE needs in the cloud native era. I think there are four main points: 1. Product Ability:It is specially emphasized that not every SRE should become a product manager, but rather consciously transform the work pain points into several functional requirements points of the product, rather than complaining, because SRE is the team closest to the online environment and reliability problems. 2. Development Ability:SRE is also a technical type of work, and obviously needs development ability. Relying solely on DEV / architecture is unreliable, and the distant water can’t put out the near fire. Without development ability, we can’t do things well in detail. If everyone does development, how to make difference with DEV? The boundary is that the DEV build the middle platform, and SRE is built on the middle platform. 3. Operations Ability:It is required to consciously use the existing tool system or create new tools to conduct all-round technical operations and make good use of data. 4. Embrace Open Source:In the cloud native era, open source may do wells after the above three abilities are ready. At this time, we need to open our eyes, sincerely embrace open source, integrate open-source products, and apply them to operations practice at low cost.
Future Outlook
There are two keypoints. The first is ability upgrading, and the second is to make operations service-oriented. In order to better adapt to the cloud native era, we always adhere to and deepen our technical belief, upgrade our team’s technical abilities, and achieve business through technical means. The second is to deepen the concept of operations servicization. The value of operations will eventually be reflected in the business. However, the best way to reflect this value is to make operations service-oriented, and maximize empower the business. Ability upgrading is to make operations servicization better. The operations servicization will open a window and give SRE more room for growth, so that they can upgrade and iterate, just like the concept of Chinese Taiji, so that the team can keep growing.

转载请注明:IT运维空间 » 运维技术 » SRE Thinking and Practice
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-

oracle跟踪sql语句
-
oracle 常用select sql语句
-

JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-
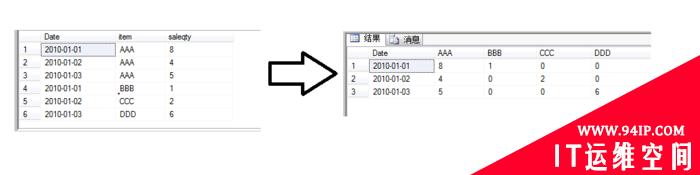
Mysql-sql行转列
-
![[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值](https://www.94ip.com/zb_users/theme/ydconcise/include/random/3.jpg)
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值




发表评论