

一、基本概念
1、机房
中心机房 当前单机房情况下的机房,除了双活的业务外,长尾业务以及没做多活的业务都在该机房。
-
单元机房
新机房,即双活新增的机房,用以承接主链路双活能力流量的机房。
2、路由
sharding_id即route_code,双活根据路由规则会转换为route_code(四轮出行为地域)。每个route_code会对应中心机房或者单元机房。网关、soa、redis、db等都会根据route_code路由到正确的机房。
二、多活的几种模式
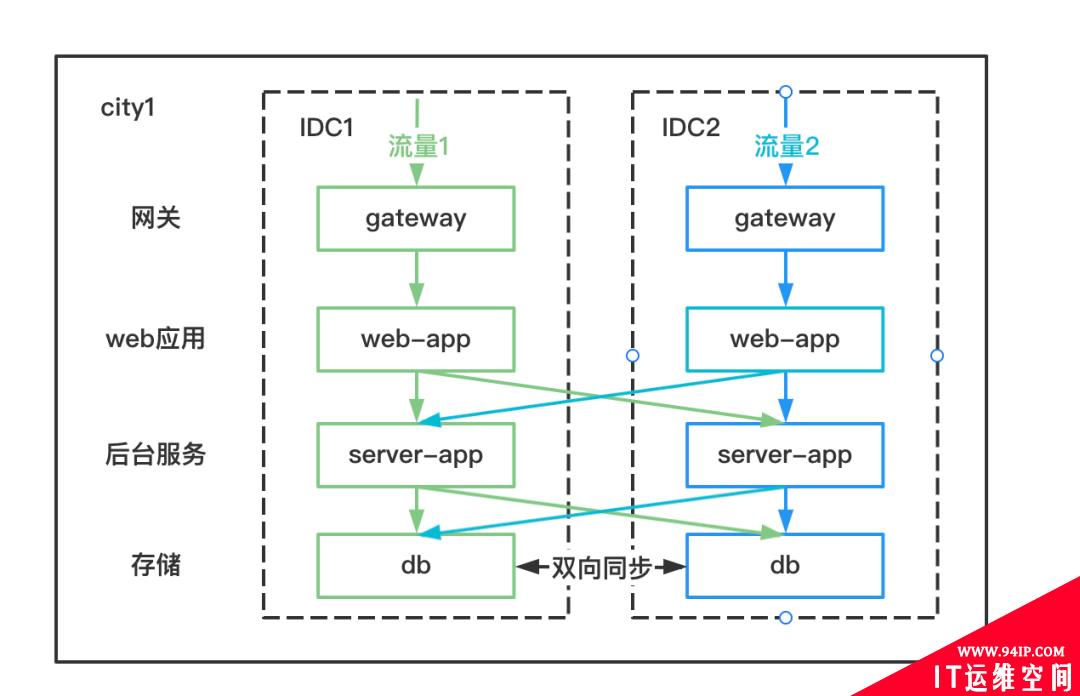
1、同城双活
在同个城市进行双活部署(两个IDC)。
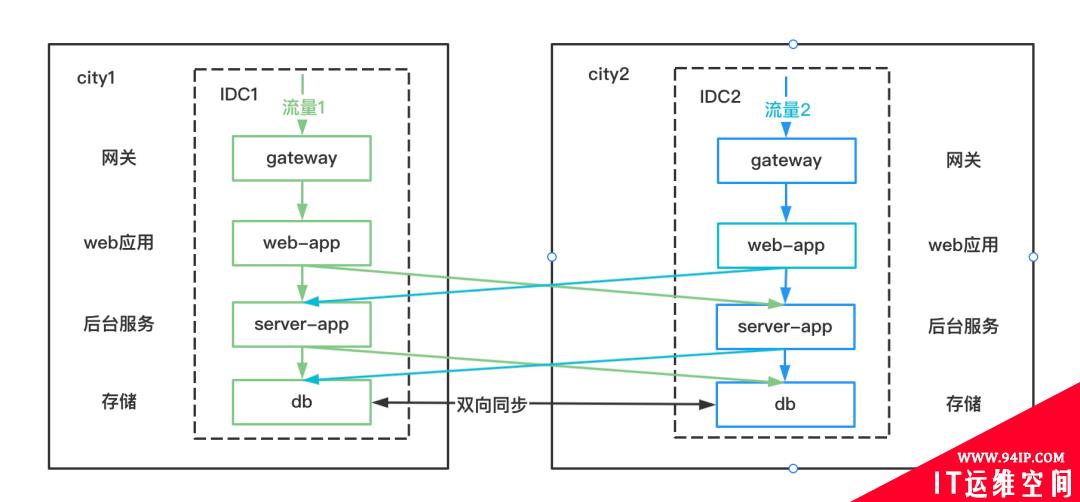
2、异地双活
在两个城市进行双活部署(每个城市一个IDC)。
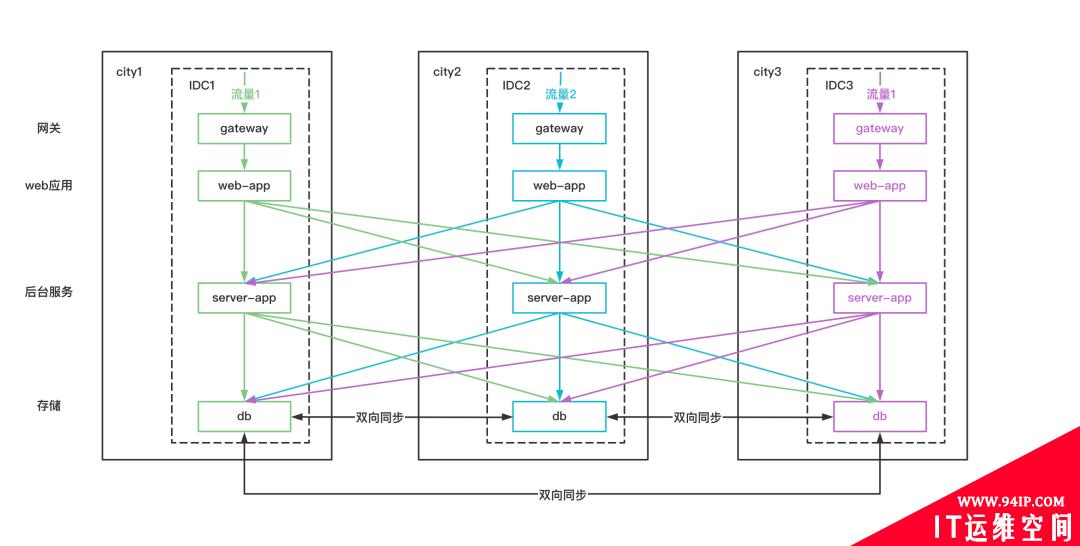
3、异地多活
在多个城市进行多IDC部署。
4、优劣势

三、单元化
大家可以考虑一个问题,一个公司,或者某个业务在tps达到几十万或者几百万在整个系统设计、架构乃至机房瓶颈就会显得极为突出。但是放眼整个国家或者全球来看,全部的tps何止百万、千万,归根结底还是因为不同的流量,在最开始就根据公司、业务、机房、地区路由到了不同的机房,而由于公司、业务之间天然是隔离的,因此每个公司的每个业务只需要处理自己的这部分tps就行。如:淘宝流量只会在阿里的应用、机房,滴滴的流量只会在滴滴的应用、机房。但是假如某个公司的某个业务的tps有一亿,假如无法做到水平无限扩容,必然是没有公司能够抗住这么大的并发的,不光是架构,即使物理机房也不允许这么大的集群(电力、场地都会有限制)。而单元化提供了理论上无限水平扩容的架构能力。
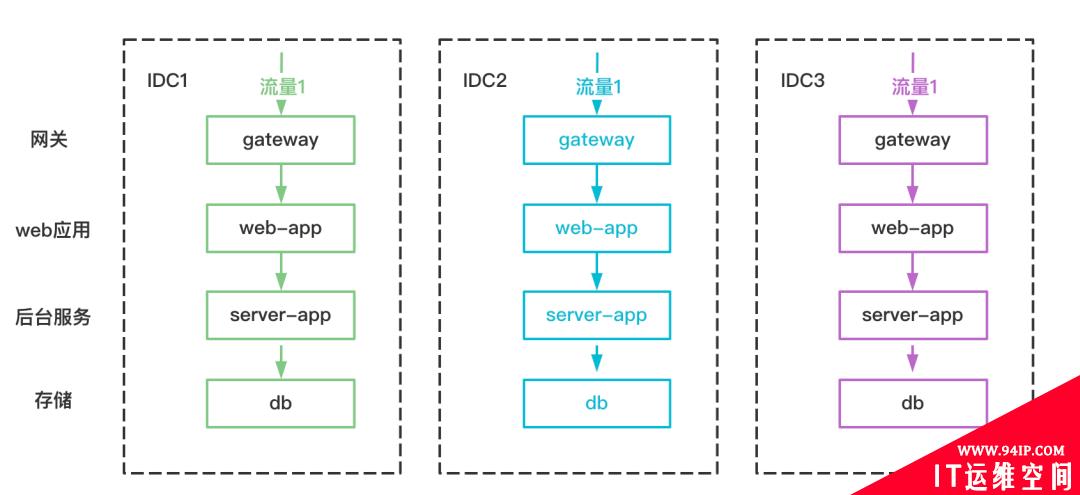
单元化可以理解为异地多活的最终形态。单元化在流量入口将流量拆分到不同的IDC,每个IDC分别承接自己的流量,且IDC之前的流量不会互相调用。单元化和区域无关,理论上做到单元化后,新增的流量完全可以新增IDC解决,而新增的IDC不会受到区域的限制,因为IDC之前不会有流量互相调用。
判断是否做到单元化,我理解只要一个标准,即是否流量能够自闭环。举个例子,如果你的A机房在上海部署,B机房很远的海外的任意一个地方,对业务也毫无影响(AB机房地域距离很长,如果无法做到自闭环,则相互调用的RT会变长,必然影响业务),那么你就可以认为是单元化成功了。
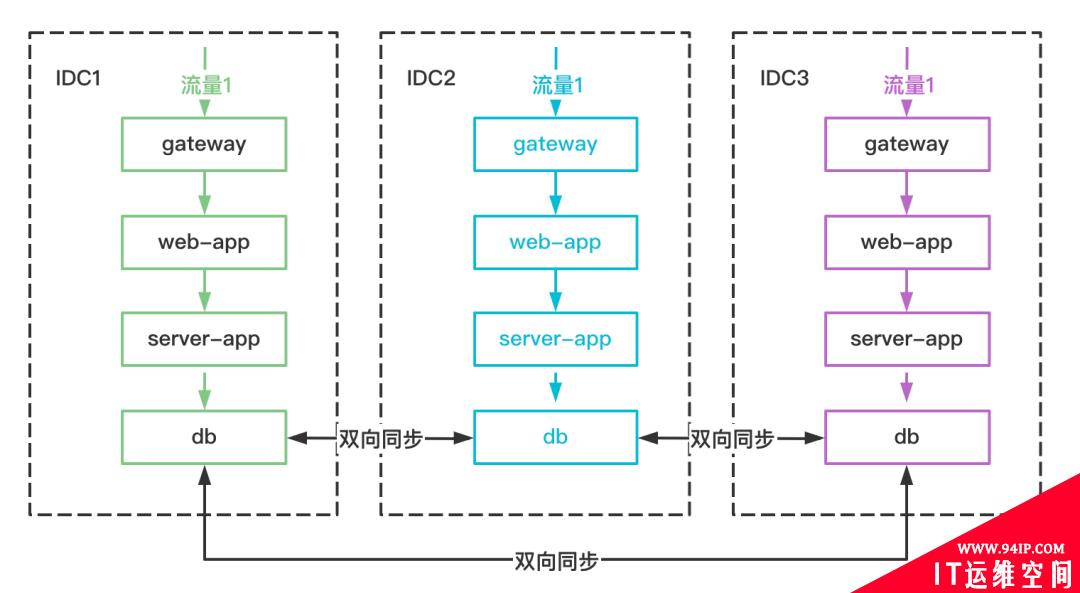
单元化流量如下:
 单元化做双活只需要在底层的数据层面进行同步即可。如下所示:
单元化做双活只需要在底层的数据层面进行同步即可。如下所示:
四、双活的流量路由规则
1、路由方式
1)随机路由 将流量按照比例随机路由到各自IDC,只需按照比例路由到每个IDC,而无任何规则。故障情况下,可以将该故障机房的流量切换到另外的IDC。 2)用户id路由 根据用户id将流量按照一定比例路由到各自IDC,每个用户的操作都会路由到指定的IDC。故障情况下,可以将该故障机房的流量按照用户切换到另外的IDC。 3)地域路由 按照用户所属城市将流量按照一定比例路由到各自的IDC,每个地方的用户操作都会路由到指定的IDC。故障情况下,可以将该故障机房的流量地域切换到另外的IDC。
2、四轮出行的选择
经过多番讨论,哈啰四轮出行最终选择了按照地域路由。 主要理由如下:随机路由在各类多活设计中都不算一个好的方案,主要原因是随机路由由于其无规律性,在多活项目中,无法做到单元化。选择地域路由而非用户维度路由,主要是由于四轮业务和电商业务存在一些区别,在电商业务中的基本操作都是基于C端用户,每个C端用户只操作自己的订单数据,因此订单数据按照用户id天然是隔离的,单元化也比较好做,但是此方案也是牺牲了B端的商家的体验,商家操作多用户订单数据必然会存在跨机房的可能性,从而影响商家体验。 作为四轮来说,买家和卖家分别为乘客和司机,是天然的双订单模型(司机订单和乘客订单),因此如果用用户id路由,则在同时操作司机订单和乘客的接口(如司机接单)中,必然会存在大量的跨机房路由(司机和乘客因为用户id不同分到不同的机房)。而如果按照地域来分,则由于出行订单跨城或者跨省的概率极低,因此该跨机房率会大大降低,且可以根据实际跨机房单量比例去人为降低跨机房数量。但是该方案也有一定缺陷,因为地域订单会在不同的时间和场景下,如:节假日、下雨天等会存在比较大的流量波动,导致同城、同省流量波动较大,从而导致机房压力大小不一致。
五、双活方案
1、中间方案
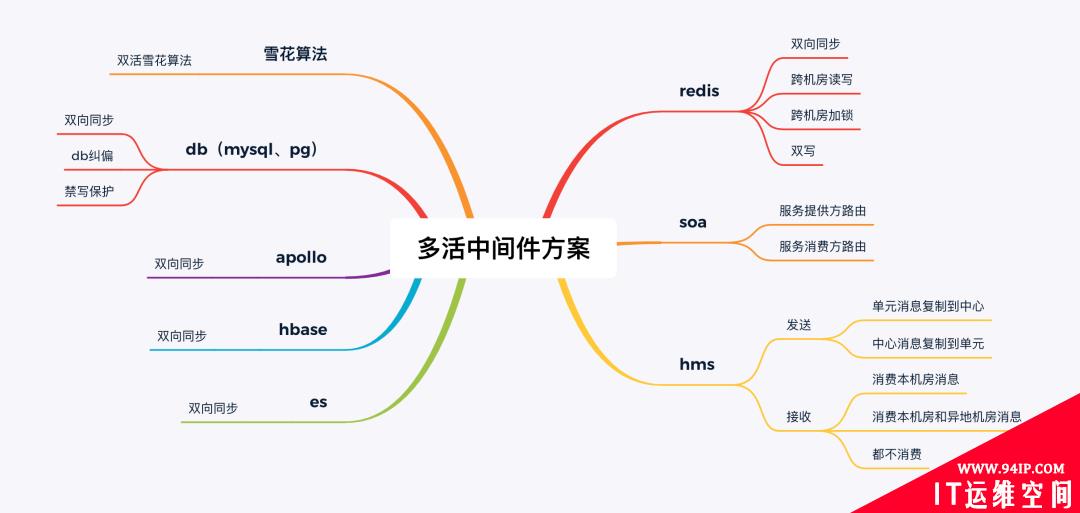 双活中间件提供的能力主要分为四类,存储、消息、soa和雪花算法。
双活中间件提供的能力主要分为四类,存储、消息、soa和雪花算法。
2、存储
存储提供的能力大部分为底层的数据双向同步。 redis的跨机房读写和跨机房加锁均是因为双订单模型无法做到单元化,提供的双活能力。 redis双写则为无双向同步能力时的临时能力。 db纠偏则是db层面指定路由,也是为了兜底,当soa路由出异常,在db层做最后的兜底(可访问跨机房数据)。 db禁写保护则是当业务开启禁写保护,非本机房的订单无法在本订单操作,也是db兜底保护的一种。
3、消息
消息则分为发送和消费。 对于发送来说,单元到中心的复制和中心到单元的复制,则都是一个机房消息复制到另外机房,也是无法单元化的一种解决方案。当然该方案也可以兼容双活应用发送消息和非双活应用消费者的问题。 消费本机房:只能消费本机房产生的消息,异地机房的复制消息无法消费。 都不消费:代表本机房和异地机房都不消费。 消费本机房和异地机房消息,则代表消息消费本机房和异地机房消息(消费双份消息)。
4、soa
soa接口需要根据特定的条件将rpc请求路由到正常的机房。 服务提供方路由则表示该路由规则由服务提供方指定。 服务消费方路由则表示该路由规则由服务消费方指定。
5、雪花算法
双活由于zk集群是两个机房的,需要在雪花算法上打上机房标识,保证全局唯一。
6、业务改造
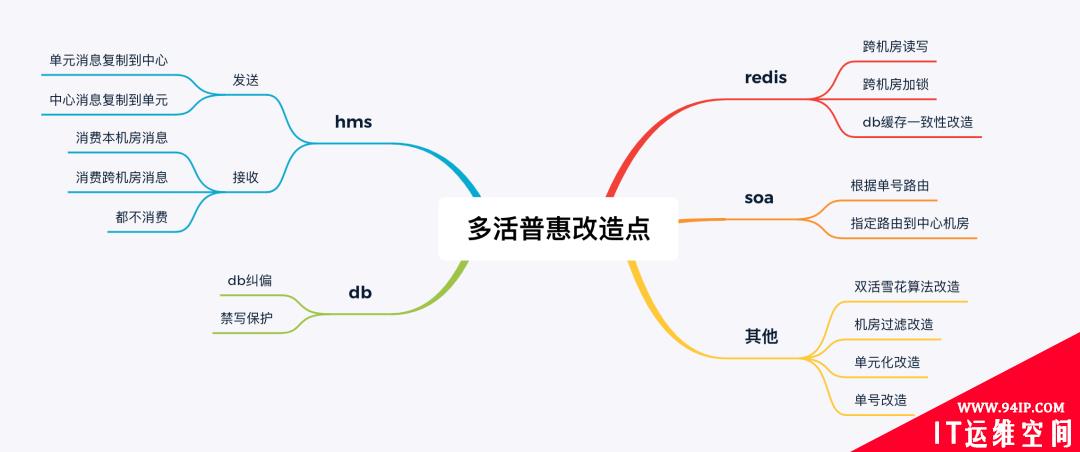 业务改造大部分是基于中间件方案的改造。而其中的部分方案是基于业务自己述求进行的一些双活改造点。
1)单元化改造
部分业务逻辑之前在单机房情况下无法做到单元化,需要对部分可单元化的业务进行改造。
2)db缓存一致性
基于订单可靠性保证,对订单数据通过binlog消息保障两机房数据一致性。
3)机房过滤改造
基于机房信息,处理非本机房逻辑,或者过滤非本机房逻辑(目前无法单元化的临时方案)。
4)单号改造
发单的时候需要将路由规则打到订单号上,在修改订单其他属性时根据订单号进行路由(保障单元化)。
业务改造大部分是基于中间件方案的改造。而其中的部分方案是基于业务自己述求进行的一些双活改造点。
1)单元化改造
部分业务逻辑之前在单机房情况下无法做到单元化,需要对部分可单元化的业务进行改造。
2)db缓存一致性
基于订单可靠性保证,对订单数据通过binlog消息保障两机房数据一致性。
3)机房过滤改造
基于机房信息,处理非本机房逻辑,或者过滤非本机房逻辑(目前无法单元化的临时方案)。
4)单号改造
发单的时候需要将路由规则打到订单号上,在修改订单其他属性时根据订单号进行路由(保障单元化)。
转载请注明:IT运维空间 » 运维技术 » 无法做单元化,异地双活也可以玩得很溜
你可能喜欢:
-
![[Oracle]复习笔记-SQL部分内容](/zb_users/upload/2023/02/25/20230213095820-63ea09bc55070.jpg)
[Oracle]复习笔记-SQL部分内容
-

oracle执行.sql文件
-

oracle 10g sqlplus,PL SQL Developer,character中文乱码解决
-
oracle跟踪sql语句
-

oracle 常用select sql语句
-
JAVA-MySQL与Oracle或者(Oracle与MySQL)之间相互拷贝数据
-

关于 mybatis-generator自定义注释生成 使用DefaultCommentGenerator重写来完成 Mybatis Generator的model生成中文注释,支持oracle和mysql(通过实现CommentGenerator接口的方法来实现)
-

如何在Oracle中一次执行多条sql语句 (.net C#)
-
Mysql-sql行转列
-
[ORACLE]查看SQL绑定变量具体值 查看SQL绑定变量值




发表评论